MySQL数据库优化的一些笔记
- - Xiaoxia[PG]之前列举记录用了下面的语句. 当记录数量很大时,有几万之后,这句SQL就很慢了. 主要是因为feed_url没有建立索引. 后来的解决方法是,把feed_url为空的,设为一个ok以外的state值,就行了. 为了计算记录总数,下面的语句会很慢. state为索引,请求用时140ms. 遍历了state='error'索引下的每一条记录.
一.使用中间件的好处
使用中间件对于主读写分离新增一个从数据库节点来说,可以不用修改代码,达到新增节点数据库而不影响到代码的修改。因为如果不用中间件,那么在代码中自己是先读写分离,如果新增节点,
你进行写操作时,你的轮询求模的数据量就要修改。但是中间件的维护也很麻烦的。
二.各种中间件
1.MYSQL官方的mysqlProxy,它可以实现读写分离,但是它使用率很低,搞笑的是MySQL官方都不推荐使用。
2.Amoeba:这是阿里巴巴工程司写的,是开源的。使用也很少。
3.阿里开源的cobar,缺点查询回来的数据没有排序,和分页,这些都要自己处理,用的少。
5.mycat:是根据cobar改造的。用的还算比较多
6.ShardingJDBC:这是当当网的。这近几年比较流行,比较牛逼。
注意:如果我们单纯的做读写分离,一般都会选择用SpringAOP去做。并不是一定使用中间件就一定好。
读写分离做完,我们数据库的压力就解决了吗?
并没有,做完读写分离,我们都知道知识一个或几个主库,多个从库,每个数据库里面的数据都是一样的。只是一份复制。
这样做的好处就是:
1。数据库可以备份。
2.减轻数据库的压力。
数据库的压力问题就缓解了吗?并没有缓解的特别厉害,当你这真正的高并发,大数据量来的时候,你做读写分离也不够用的。MySQL单表能承受多少数据量呢?
实践来看的话,大概也就7000W-1亿,这根据字段量,和字段里面存的东西,这数据是根据业务走的,不一定那么精确。
当达到这个数量级的时候你的多表关联查询什么的,即便优化到位,我说的优化,第一是索引一定要设置合理,第二SQL优化,但是SQL优化做的很有限。
到这个数据量你去关联那么两三个表,基本都是在5S,10S甚至更长的时间。
这时候就要考虑别的办法了。走到这一步,那该怎么办呢?
那么就要进行分库分表:
1.垂直拆分:
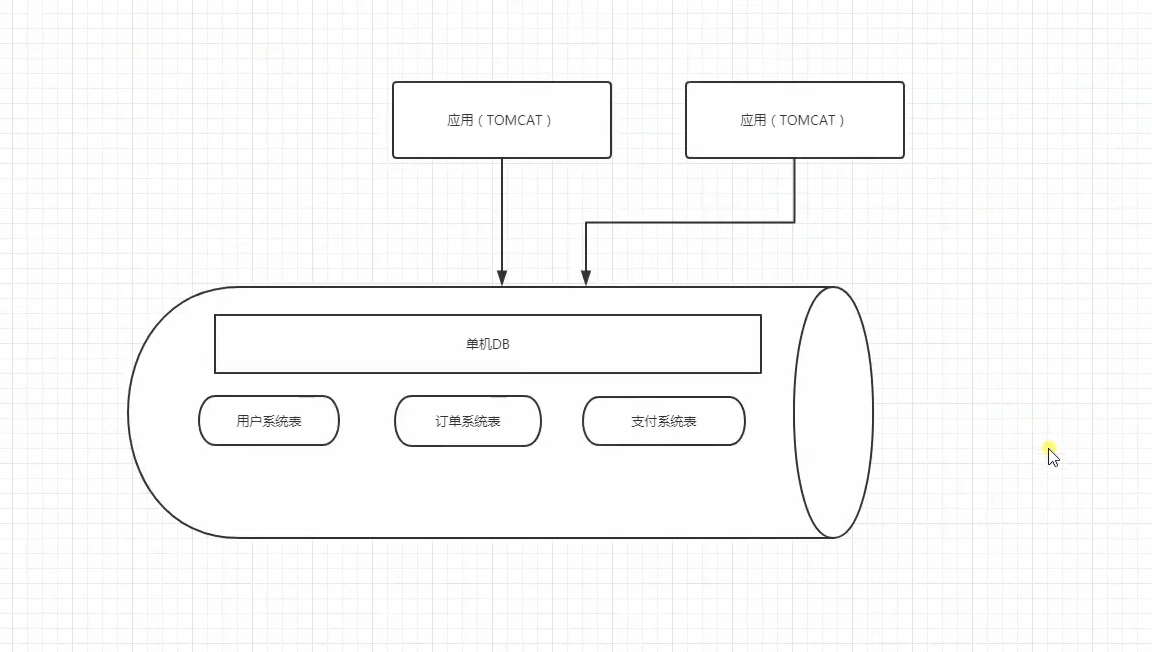
基于领域模型做数据的垂直切分是一种最佳实践。如将订单、用户、支付等领域模型划分到不同的DB库里面。前提必须各领域数据之间join展示场景较少,在这种情况下分库能获得很高的价值,同时各个系统之间的扩展性得到很大程度的提高。
缺点:如果在拆分之前,系统中很多列表和详情页所需的数据是可以通过sql join来完成的。而拆分后,数据库可能是分布式在不同实例和不同的主机上,join将变得非常麻烦。而且基于架构规范,性能,安全性等方面考虑,一般是禁止跨库join的。
那该怎么办呢?首先要考虑下垂直分库的设计问题,如果可以调整,那就优先调整。
解决办法:
1.建立全局表:系统中可能出现所有模块都可能会依赖到的一些表。比较类似我们理解的“数据字典”。为了避免跨库join查询,我们可以将这类表在其他每个数据库中均保存一份。这种做法叫做建立全局表
同时,这类数据通常也很少发生修改(几乎不会),一般不用太担心“一致性”问题。
2.进行数据同步:比如,用户库中的tab_a表和订单库中tbl_b有关联,可以定时将指定的表做同步。当然,同步本来会对数据库带来一定的影响,需要性能影响和数据时效性中取得一个平衡。这样来避免复杂的跨库查询。
3.系统层面组装:调用不同模块的组件或者服务,获取到数据并进行字段拼装。不要想着这很容易,实践起来可真没有那么容易,尤其是数据库设计上存在问题但又无法轻易调整的时候。具体情况通常会比较复杂。
组装的时候要避免循环调用服务,循环RPC,循环查询数据库,最好一次性返回所有信息,在代码里做组装。
4.适当的进行字段冗余:比如“订单表”中保存“卖家Id”的同时,将卖家的“Name”字段也冗余,这样查询订单详情的时候就不需要再去查询“卖家用户表”。
如下图:
拆分前:
拆分后:

这样的话能够缓解一下压力,我们还可以对每一个独立的DB在进行读写分离。
当然拆分也会出现问题的。比如说分布式事务。比如支付系统支付失败了回滚,那么你订单系统也要回滚的。但是你们都不在同一个库里面,这是就需要分布式事务了。
如果走到这一步,你的系统还是缓解不了压力,那么说明你这系统比较厉害了。说明你公司在你的行业里面能叫的上名字的了。
那么我们就要进行水平拆分了。
2.水平拆分:垂直切分缓解了原来单集群(所有的数据库都存在一张表里,)的压力,但是在抢购时依然捉襟见肘。原有的订单模型已经无法满足业务需求,于是就要进行水平分表也称为横向分表,
比较容易理解,就是将表中不同的数据行按照一定规律分布到不同的数据库表中(这些表保存在同一个数据库中),这样来降低单表数据量,优化查询性能。
最常见的方式就是通过 主键或者 时间等字段进行 Hash和 取模后拆分。
如下图:
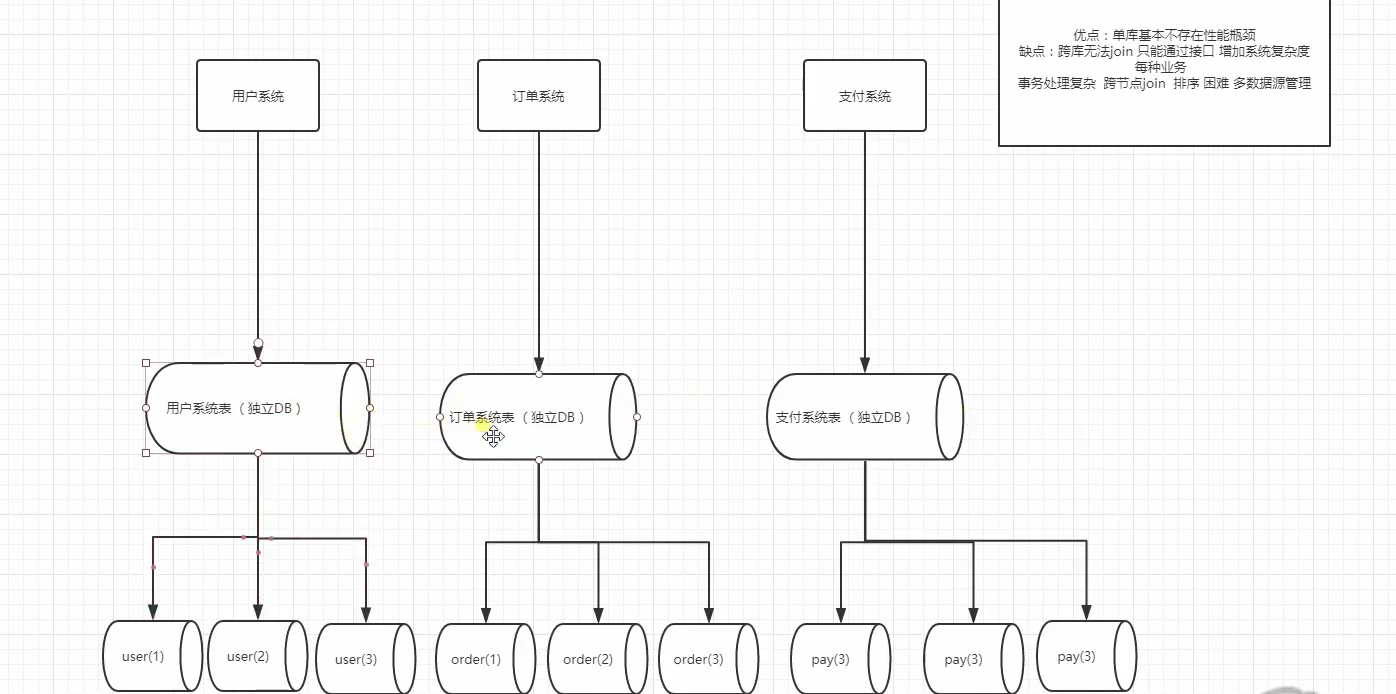
如果数据压力还是比较大怎么呢?,还能怎么办,继续进行水平拆分咯,比如,user(1)user(2)user(3)继续惊醒水平拆分。
1. 常见分片规则问题
1。一致性hash: 依据Sharding Key对5取模,根据余数将数据散落到目标表中。比如将数据均匀的分布在5张user表中,如下图:

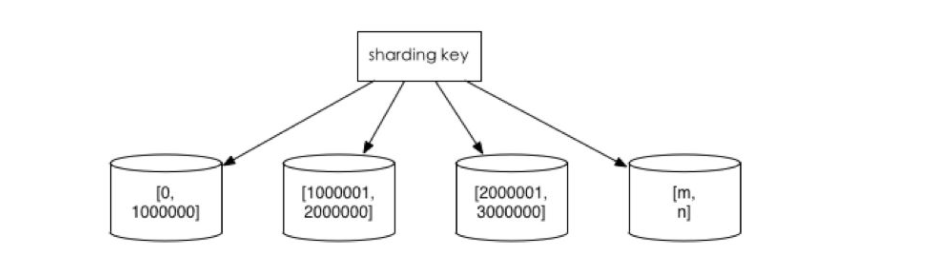
2.范围切分:比如按照时间区间或ID区间来切分。
优点:单表大小可控,天然水平扩展。
缺点:无法解决集中写入瓶颈的问题
如下图:
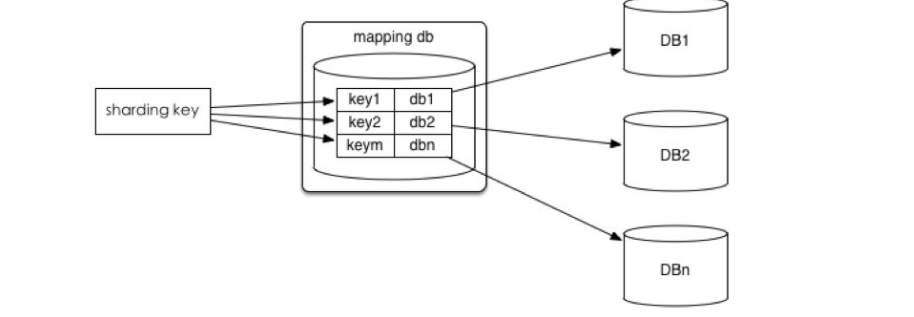
3.将ID和库的Mapping关系记录在一个单独的库中。
优点:ID和库的Mapping算法可以随意更改。
缺点:引入额外的单点。
如下图:
很少有项目会在初期就开始考虑分片设计的,一般都是在业务高速发展面临性能和存储的瓶颈时才会提前准备。因此,不可避免的就需要考虑历史数据迁移的问题。
一般做法就是通过程序先读出历史数据,这些数据量非常大,不涉及事务,实时性要求低,这是你就要考虑一下非关系数据库了,比如MongoDB,Hbase,这些数据库
扩展性非常好,这些NoSQL天然就是分片的。弹性非常好。然后按照指定的分片规则再将数据写入到各个分片节点中。
这里还要知道一下什么是OLTP,OLAP:
OLTP(on-line transaction processing)主要是执行基本日常的事务处理,比如数据库记录的增删查改。比如在银行的一笔交易记录,就是一个典型的事务。
OLTP的特点一般有:
1.实时性要求高。我记得之前上大学的时候,银行异地汇款,要隔天才能到账,而现在是分分钟到账的节奏,说明现在银行的实时处理能力大大增强。
2.数据量不是很大,生产库上的数据量一般不会太大,而且会及时做相应的数据处理与转移。
3.交易一般是确定的,比如银行存取款的金额肯定是确定的,所以OLTP是对确定性的数据进行存取
4.高并发,并且要求满足ACID原则。比如两人同时操作一个银行卡账户,比如大型的购物网站秒杀活动时上万的QPS请求。
联机分析处理OLAP(On-Line Analytical Processing)是数据仓库系统的主要应用,支持复杂的分析操作,侧重决策支持,并且提供直观易懂的查询结果。典型的应用就是复杂的动态的报表系统。
OLAP的特点一般有:
1.实时性要求不是很高,比如最常见的应用就是天级更新数据,然后出对应的数据报表。
2.数据量大,因为OLAP支持的是动态查询,所以用户也许要通过将很多数据的统计后才能得到想要知道的信息,例如时间序列分析等等,所以处理的数据量很大;
3.OLAP系统的重点是通过数据提供决策支持,所以查询一般都是动态,自定义的。所以在OLAP中,维度的概念特别重要。一般会将用户所有关心的维度数据,存入对应数据平台
在分库分表的情况下,为了快速(分页)查询数据,分表策略的选择就显得非常重要了,需要尽最大限度将需要跨范围查询的数据尽量集中,多数情况下在我们做了最大限度的努力之后,数据仍然可能是分布式的。
为了进一步提高查询的性能,维持查询的中间变量信息是我们在分库分表模式下提高分页查询速度的另一个手段:我们每次翻页查询时,通过中间信息的分析,就可以直接定位到目标表的目标位置,通过这种方式提供了近似于在单表模式下的分页查询能力。
但另一方面也需要在业务上做出一定的牺牲:限制查询区段,提高检索速度。
如下图:
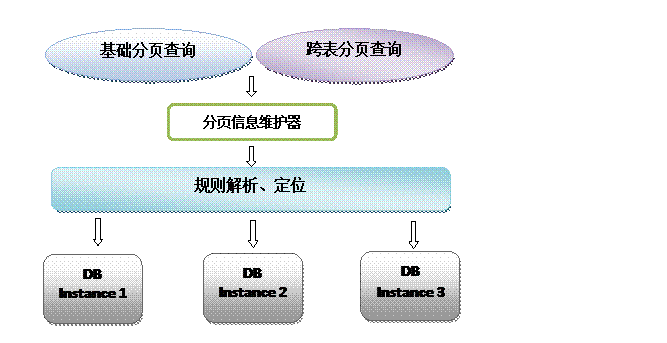
在使用Max、Min、Sum、Count之类的函数进行统计和计算的时候,需要先在每个分片数据源上执行相应的函数处理,然后再将各个结果集进行二次处理,最终再将处理结果返回。
Join是关系型数据库中最常用的特性,但是在分片集群中,join也变得非常复杂。应该尽量避免跨分片的join查询(这种场景,比上面的跨分片分页更加复杂,而且对性能的影响很大)。
通常有以下 几种方式来避免:
1.全局表
全局表的概念之前在“垂直分库”时提过。基本思想一致,就是把一些类似数据字典又可能会产生join查询的表信息放到各分片中,从而避免跨分片的join。
2.ER分片
在关系型数据库中,表之间往往存在一些关联的关系。如果我们可以先确定好关联关系,并将那些存在关联关系的表记录存放在同一个分片上,那么就能很好的避免跨分片join问题。在一对多关系的情况下,我们通常会选择按照数据较多的那一方进行拆分。
3.内存计算
随着spark内存计算的兴起,理论上来讲,很多跨数据源的操作问题看起来似乎都能够得到解决。可以将数据丢给spark集群进行内存计算,最后将计算结果返回。
并非所有表都需要水平拆分,要看增长的类型和速度,水平拆分是大招,拆分后会增加开发的复杂度,不到万不得已不使用。
在大规模并发的业务上,尽量做到在线查询和离线查询隔离,交易查询和运营/客服查询隔离。
拆分维度的选择很重要,要尽可能在解决拆分前问题的基础上,便于开发。
数据库没你想象的那么坚强,需要保护,尽量使用简单的、良好索引的查询,这样数据库整体可控,也易于长期容量规划以及水平扩展。