直白介绍卷积神经网络(CNN) - 文章 - 伯乐在线
- -什么是卷积神经网络,它为何重要. 神经网络的一种,它在图像识别和分类等领域已被证明非常有效. 卷积神经网络除了为机器人和自动驾驶汽车的视觉助力之外,还可以成功识别人脸,物体和交通标志. 图1所示,卷积神经网络能够识别图片的场景并且提供相关标题(“足球运动员正在踢足球”),. 图2则是利用卷积神经网络识别日常物品、人类和动物的例子.
卷积神经网络(也称作 ConvNets或 CNN)是 神经网络的一种,它在图像识别和分类等领域已被证明非常有效。 卷积神经网络除了为机器人和自动驾驶汽车的视觉助力之外,还可以成功识别人脸,物体和交通标志。

图1
如 图1所示,卷积神经网络能够识别图片的场景并且提供相关标题(“足球运动员正在踢足球”), 图2则是利用卷积神经网络识别日常物品、人类和动物的例子。最近,卷积神经网络在一些自然语言处理任务(如语句分类)中也发挥了很大作用。

图2
因此,卷积神经网络是当今大多数机器学习实践者的重要工具。但是,理解卷积神经网络并开始尝试运用着实是一个痛苦的过程。本文的主要目的是了解卷积神经网络如何处理图像。
对于刚接触神经网络的人,我建议大家先阅读这篇 关于多层感知机的简短教程,了解其工作原理之后再继续阅读本文。多层感知机即本文中的“完全连接层”。
LeNet 是最早推动深度学习领域发展的卷积神经网络之一。这项由 Yann LeCun 完成的开创性工作自1988年以来多次成功迭代之后被命名为 LeNet5。当时 LeNet 框架主要用于字符识别任务,例如阅读邮政编码,数字等。
接下来,我们将直观地了解 LeNet 框架如何学习识别图像。 近年来有人提出了几种基于 LeNet 改进的新框架,但是它们的基本思路与 LeNet 并无差别,如果您清楚地理解了 LeNet,那么对这些新的框架理解起来就相对容易很多。

图3: 一个简单的卷积神经网络
图 3中的卷积神经网络在结构上与原始的 LeNet 类似,并将输入图像分为四类:狗,猫,船或鸟(原始的 LeNet 主要用于字符识别任务)。 从上图可以看出,接收船只图像作为输入时,神经网络在四个类别中正确地给船只分配了最高概率值(0.94)。输出层中所有概率的总和应该是1(之后会做解释)。
图 3 的卷积神经网络中有四个主要操作:
这些操作是所有卷积神经网络的基本组成部分,因此了解它们的工作原理是理解卷积神经网络的重要步骤。下面我们将尝试直观地理解每个操作。
实质上,每张图片都可以表示为由像素值组成的矩阵。
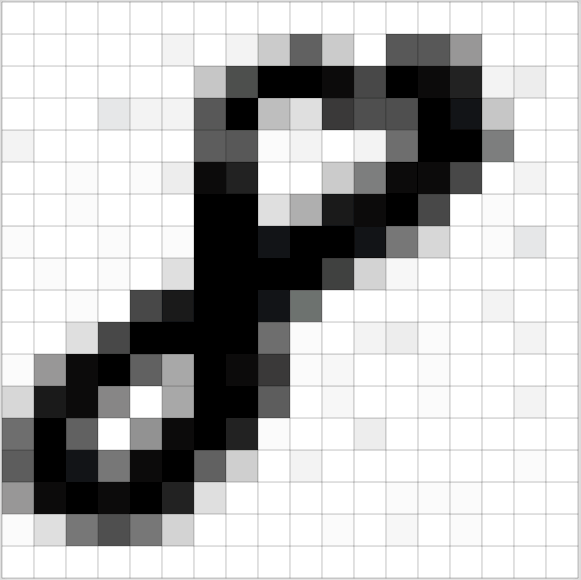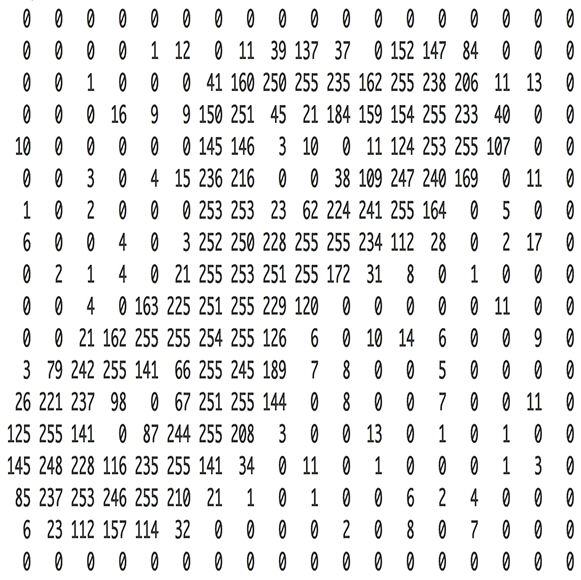
图4: 每张图片就是一个像素矩阵
通道(channel)是一个传统术语,指图像的一个特定成分。标准数码相机拍摄的照片具有三个通道——红,绿和蓝——你可以将它们想象为三个堆叠在一起的二维矩阵(每种颜色一个),每个矩阵的像素值都在0到255之间。
而 灰度图像只有一个通道。 鉴于本文的科普目的,我们只考虑灰度图像,即一个代表图像的二维矩阵。矩阵中每个像素值的范围在0到255之间——0表示黑色,255表示白色。
卷积神经网络的名字来源于 “卷积”运算。在卷积神经网络中,卷积的主要目的是从输入图像中提取特征。通过使用输入数据中的小方块来学习图像特征,卷积保留了像素间的空间关系。我们在这里不会介绍卷积的数学推导,但会尝试理解它是如何处理图像的。
正如前文所说,每个图像可以被看做像素值矩阵。考虑一个像素值仅为0和1的5 × 5大小的图像(注意,对于灰度图像,像素值范围从0到255,下面的绿色矩阵是像素值仅为0和1的特殊情况):
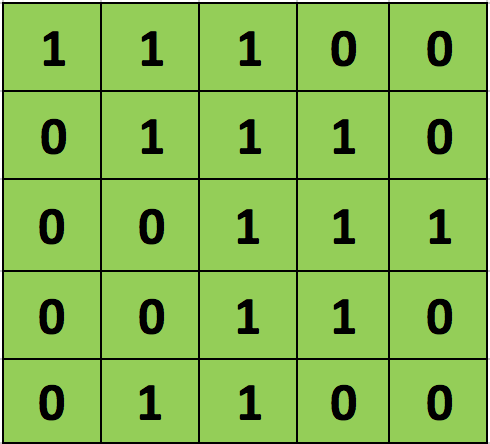
另外,考虑另一个 3×3 矩阵,如下图所示:

上述5 x 5图像和3 x 3矩阵的卷积计算过程如 图 5中的动画所示:
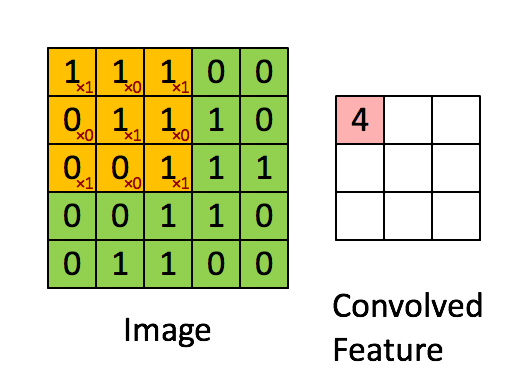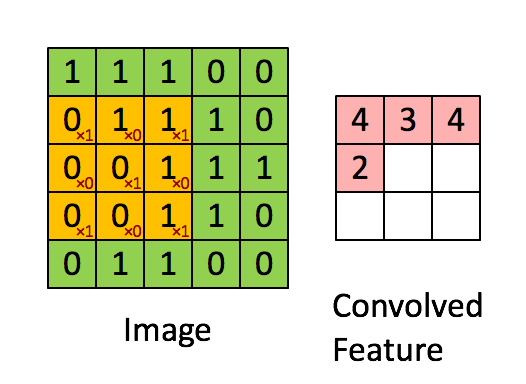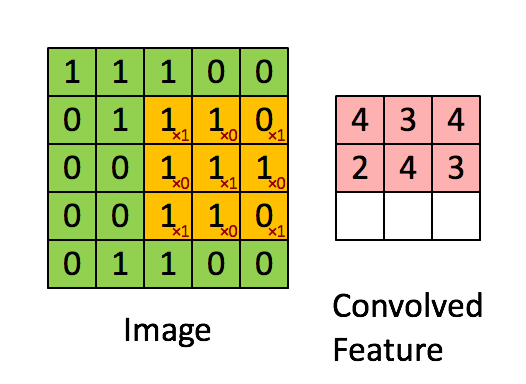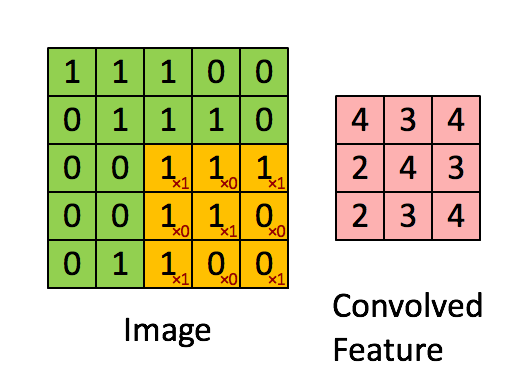
图5:卷积操作。输出矩阵称作“卷积特征”或“特征映射”
我们来花点时间理解一下上述计算是如何完成的。将橙色矩阵在原始图像(绿色)上以每次1个像素的速率(也称为“步幅”)移动,对于每个位置,计算两个矩阵相对元素的乘积并相加,输出一个整数并作为最终输出矩阵(粉色)的一个元素。注意,3 × 3矩阵每个步幅仅能“看到”输入图像的一部分。
在卷积神经网路的术语中,这个3 × 3矩阵被称为“ 过滤器”或“核”或“特征探测器”,通过在图像上移动过滤器并计算点积得到的矩阵被称为“卷积特征”或“激活映射”或“ 特征映射”。重要的是要注意,过滤器的作用就是原始输入图像的特征检测器。
从上面的动画可以明显看出,对于同一张输入图像,不同的过滤器矩阵将会产生不同的特征映射。例如,考虑如下输入图像:

在下表中,我们可以看到上图在不同过滤器下卷积的效果。如图所示,只需在卷积运算前改变过滤器矩阵的数值就可以执行边缘检测,锐化和模糊等不同操作 [ 8] —— 这意味着不同的过滤器可以检测图像的不同特征,例如边缘, 曲线等。更多此类示例可在 这里8.2.4节中找到。

另一个理解卷积操作的好方法可以参考下面 图 6中的动画:

图6: 卷积操作
一个过滤器(红色边框)在输入图像上移动(卷积操作)以生成特征映射。在同一张图像上,另一个过滤器(绿色边框)的卷积生成了不同的特征图,如图所示。需要注意到,卷积操作捕获原始图像中的局部依赖关系很重要。还要注意这两个不同的过滤器如何从同一张原始图像得到不同的特征图。请记住,以上图像和两个过滤器只是数值矩阵。
实际上,卷积神经网络在训练过程中会自己 学习这些过滤器的值(尽管在训练过程之前我们仍需要指定诸如过滤器数目、大小,网络框架等参数)。我们拥有的过滤器数目越多,提取的图像特征就越多,我们的网络在识别新图像时效果就会越好。
特征映射(卷积特征)的大小由我们在执行卷积步骤之前需要决定的三个参数[ 4]控制:
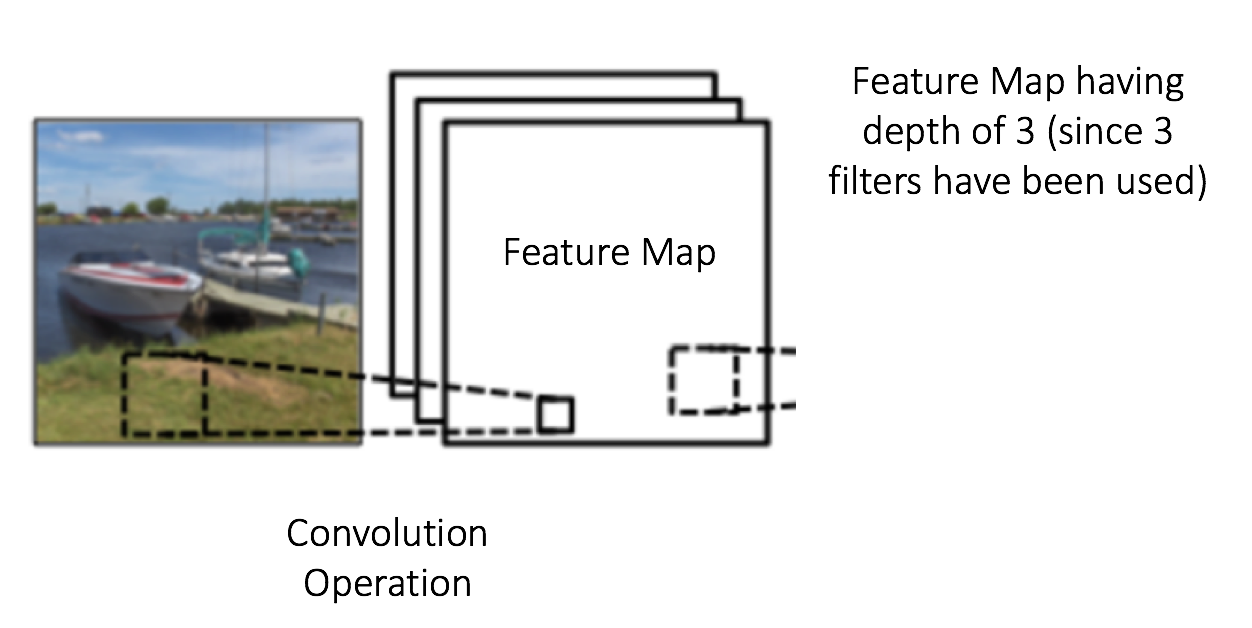
图7
如上文 图 3所示,每次卷积之后,都进行了另一项称为 ReLU 的操作。ReLU 全称为修正线性单元(Rectified Linear Units),是一种非线性操作。 其输出如下图所示:
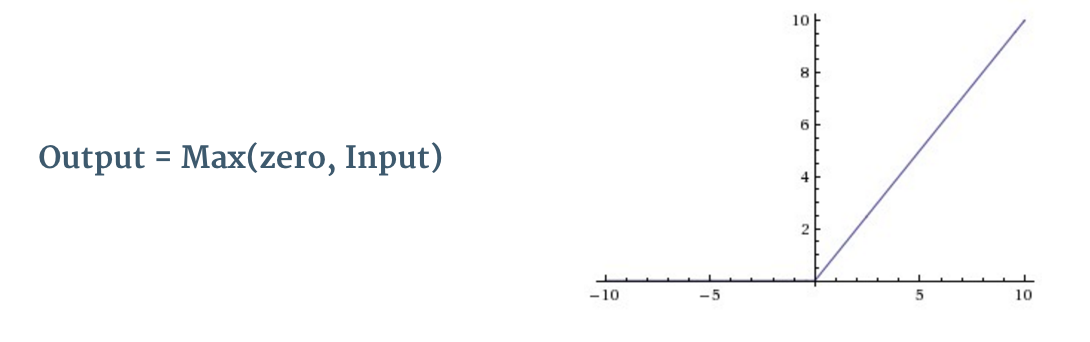
图8: ReLU 函数
ReLU 是一个针对元素的操作(应用于每个像素),并将特征映射中的所有负像素值替换为零。ReLU 的目的是在卷积神经网络中引入非线性因素,因为在实际生活中我们想要用神经网络学习的数据大多数都是非线性的(卷积是一个线性运算 —— 按元素进行矩阵乘法和加法,所以我们希望通过引入 ReLU 这样的非线性函数来解决非线性问题)。
从 图 9可以很清楚地理解 ReLU 操作。它展示了将 ReLU 作用于 图 6中某个特征映射得到的结果。这里的输出特征映射也被称为“修正”特征映射。

图9: ReLU 操作
其他非线性函数诸如 tanh或 sigmoid也可以用来代替 ReLU,但是在大多数情况下,ReLU 的表现更好。
空间池化(也称为子采样或下采样)可降低每个特征映射的维度,并保留最重要的信息。空间池化有几种不同的方式:最大值,平均值,求和等。
在最大池化的情况下,我们定义一个空间邻域(例如,一个2 × 2窗口),并取修正特征映射在该窗口内最大的元素。当然我们也可以取该窗口内所有元素的平均值(平均池化)或所有元素的总和。在实际运用中,最大池化的表现更好。
图 10展示了通过2 × 2窗口在修正特征映射(卷积+ ReLU 操作后得到)上应用最大池化操作的示例。
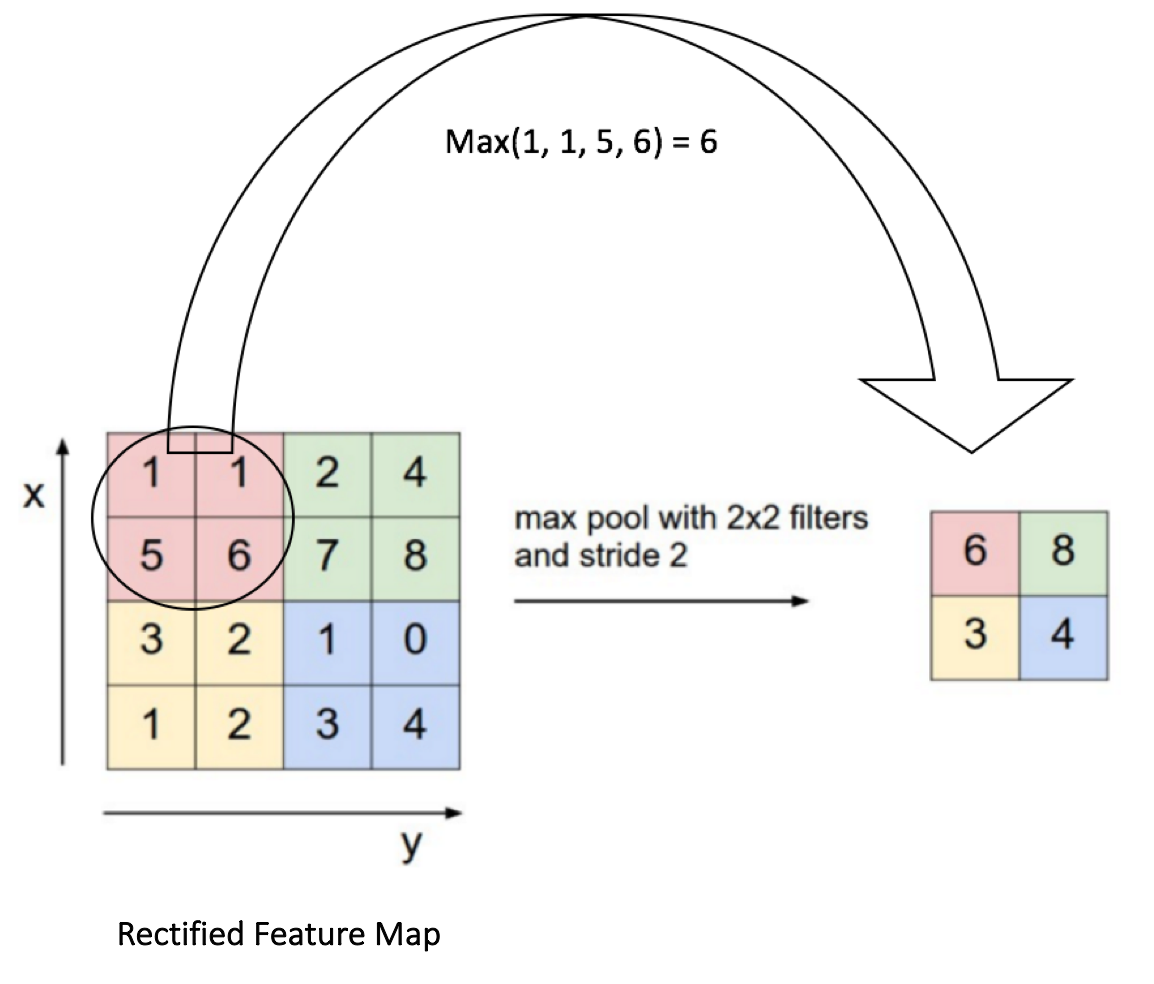
图10: 最大池化
我们将2 x 2窗口移动2个单元格(也称为“步幅”),并取每个区域中的最大值。如 图 10所示,这样就降低了特征映射的维度。
在 图 11所示的网络中,池化操作分别应用于每个特征映射(因此,我们从三个输入映射中得到了三个输出映射)。
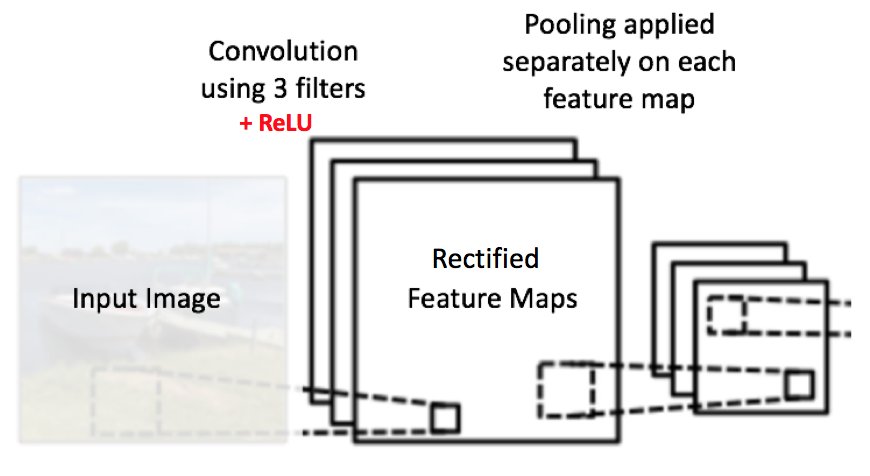
图11: 在修正特征映射上应用池化
图 12展示了我们对 图 9中经过 ReLU 操作之后得到的修正特征映射应用池化之后的效果。
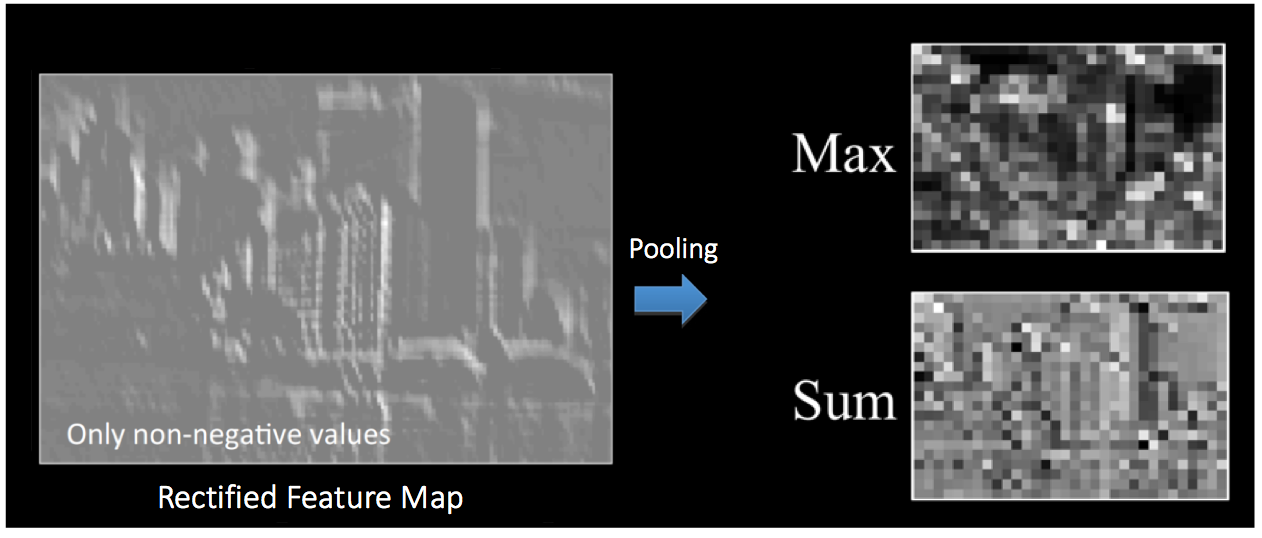
图12: 池化
池化的作用是逐步减少输入的空间大小[ 4]。具体来说有以下四点:

图13
目前为止,我们已经了解了卷积,ReLU 和池化的工作原理。这些是卷积神经网络的基本组成部分,理解这一点很重要。如 图 13所示,我们有两个由卷积,ReLU 和 Pooling 组成的中间层 —— 第二个卷积层使用六个过滤器对第一层的输出执行卷积,生成六个特征映射。然后将 ReLU 分别应用于这六个特征映射。接着,我们对六个修正特征映射分别执行最大池化操作。
这两个中间层的作用都是从图像中提取有用的特征,在网络中引入非线性因素,同时对特征降维并使其在尺度和平移上等变[ 18]。
第二个池化层的输出即完全连接层的输入,我们将在下一节讨论。
完全连接层是一个传统的多层感知器,它在输出层使用 softmax 激活函数(也可以使用其他分类器,比如 SVM,但在本文只用到了 softmax)。“完全连接”这个术语意味着前一层中的每个神经元都连接到下一层的每个神经元。 如果对多层感知器不甚了解,我建议您阅读 这篇文章。
卷积层和池化层的输出代表了输入图像的高级特征。完全连接层的目的是利用这些基于训练数据集得到的特征,将输入图像分为不同的类。例如,我们要执行的图像分类任务有四个可能的输出,如 图 14所示(请注意,图14没有展示出完全连接层中节点之间的连接)
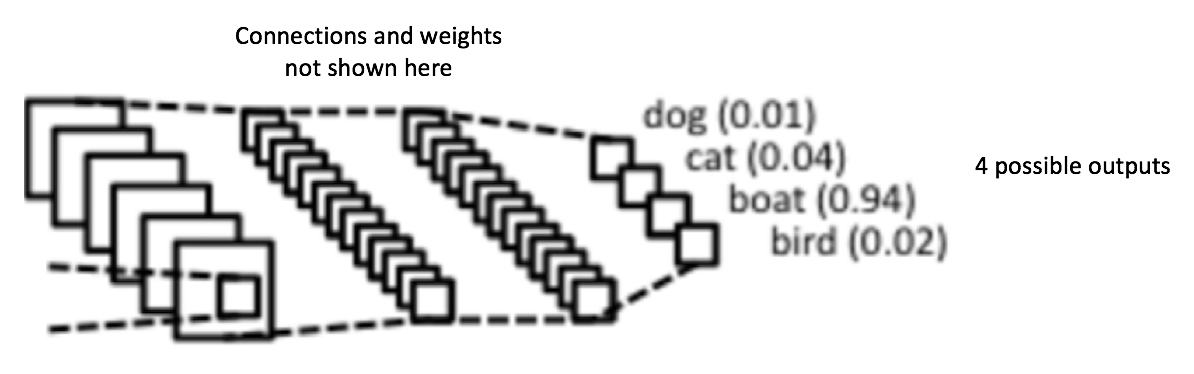
图14: 完全连接层——每个节点都与相邻层的其他节点连接
除分类之外,添加完全连接层也是一个(通常来说)比较简单的学习这些特征非线性组合的方式。卷积层和池化层得到的大部分特征对分类的效果可能也不错,但这些特征的组合可能会更好[ 11]。
完全连接层的输出概率之和为1。这是因为我们在完全连接层的输出层使用了 softmax 激活函数。Softmax 函数取任意实数向量作为输入,并将其压缩到数值在0到1之间,总和为1的向量。
如上所述,卷积+池化层用来从输入图像提取特征,完全连接层用来做分类器。
注意,在 图 15中,由于输入图像是船,对于船类目标概率为1,其他三个类为0
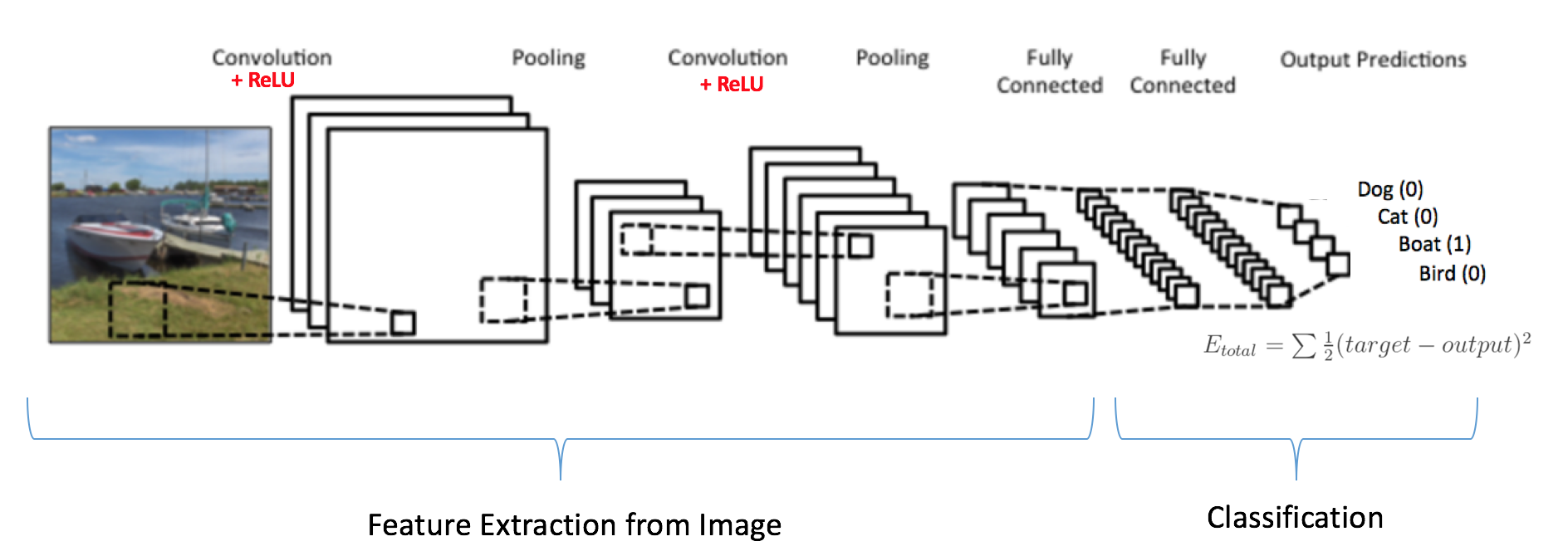
图15:训练卷积神经网络
卷积网络的整体训练过程概括如下:
通过以上步骤就可以 训练出卷积神经网络 —— 这实际上意味着卷积神经网络中的所有权重和参数都已经过优化,可以对训练集中的图像进行正确分类。
当我们给卷积神经网络中输入一个新的(未见过的)图像时,网络会执行前向传播步骤并输出每个类的概率(对于新图像,计算输出概率所用的权重是之前优化过,并能够对训练集完全正确分类的)。如果我们的训练集足够大,神经网络会有很好的泛化能力(但愿如此)并将新图片分到正确的类里。
注1 :为了给大家提供一个直观的训练过程,上述步骤已经简化了很多,并且忽略了数学推导过程。如果想要数学推导以及对卷积神经网络透彻的理解,请参阅 [ 4] 和 [ 12]。
注 2 :上面的例子中,我们使用了两组交替的卷积和池化层。但请注意,这些操作可以在一个卷积神经网络中重复执行多次。实际上,现在效果最好的一些卷积神经网络都包含几十个卷积和池化层! 另外,每个卷积层之后的池化层不是必需的。从下面的 图 16中可以看出,在进行池化操作之前,我们可以连续进行多个卷积 + ReLU 操作。另外请注意图16卷积神经网络的每一层是如何展示的。

图16
一般来说,卷积步骤越多,神经网络能够学习识别的特征就更复杂。例如,在图像分类中,卷积神经网络在第一层可能会学习检测原始像素的边缘,然后在第二层利用这些边缘检测简单形状,然后在更高级的层用这些形状来检测高级特征,例如面部形状 [ 14]。 图 17演示了这个过程 —— 这些特征是使用 卷积深度信念网络学习的,这张图片只是为了演示思路(这只是一个例子:实际上卷积过滤器识别出来的对象可能对人来说并没有什么意义)。
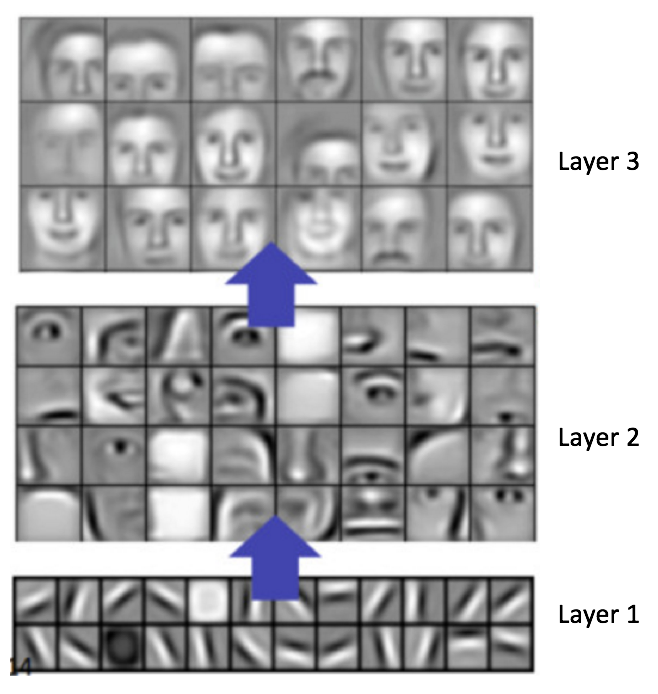
图17: 卷积深度信念网络学习特征
Adam Harley 创建了一个基于 MNIST 手写数字数据集 [ 13]训练卷积神经网络的可视化。我强烈推荐大家 使用它来了解卷积神经网络的工作细节。
我们在下图中可以看到神经网络对于输入数字“8”的具体操作细节。请注意, 图 18中并未单独显示ReLU操作。

图18:基于手写数字训练卷积神经网络的可视化
输入图像包含 1024 个像素点(32 × 32 图像),第一个卷积层(卷积层1)由六个不同的5 × 5(步幅为1)过滤器与输入图像卷积而成。如图所示,使用六个不同的过滤器得到深度为六的特征映射。
卷积层1之后是池化层1,它在卷积层1中的六个特征映射上分别进行2 × 2最大池化(步幅为2)。将鼠标指针移动到池化层的任意像素上,可以观察到它来自于2 x 2网格在前一个卷积层中的作用(如 图 19所示)。注意到2 x 2网格中具有最大值(最亮的那个)的像素点会被映射到池化层。

图19:池化操作可视化
池化层1之后是十六个执行卷积操作的5 × 5(步幅为1)卷积过滤器。然后是执行2 × 2最大池化(步幅为2)的池化层2。 这两层的作用与上述相同。
然后有三个完全连接(FC)层:
注意,在 图 20中,输出层的10个节点每一个都连接到第二个完全连接层中的全部100个节点(因此称为完全连接)。
另外,注意为什么输出层中唯一明亮的节点是’8’ —— 这意味着神经网络对我们的手写数字进行了正确分类(节点亮度越高表示它的输出更高,即8在所有数字中具有最高的概率)。

图20:完全连接层可视化
该可视化系统的 3D 版本 在此。
卷积神经网络始于20世纪90年代初。我们已经讨论了LeNet,它是最早的卷积神经网络之一。下面列出了其他一些有影响力的神经网络框架 [ 3] [ 4]。
本文中,我尝试着用一些简单的术语解释卷积神经网络背后的主要概念,同时简化/略过了几个细节部分,但我希望这篇文章能够让你直观地理解其工作原理。
本文最初是受 Denny Britz 《 理解卷积神经网络在自然语言处理上的运用》这篇文章的启发(推荐阅读),文中的许多解释是基于这篇文章的。为了更深入地理解其中一些概念,我鼓励您阅读 斯坦福大学卷积神经网络课程的 笔记以及一下参考资料中提到的其他很棒的资源。如果您对上述概念的理解遇到任何问题/建议,请随时在下面留言。
文中所使用的所有图像和动画均属于其各自的作者,陈列如下。