背景
Airbnb已经将它的基础设施迁移到了SOA架构上。SOA提供了诸多好处,例如研发人员分工更专业化,可以快速迭代等。然而,由于它给数据完整性带来了更多的困难,对于订单及支付应用而言也面临更多挑战。一次API调用了某个服务,又会调用到下游服务的API,每个服务都会更新状态,因此也会产生副作用,这就相当于在执行一个复杂的分布式事务。
为了保持所有服务的一致性,就可能会使用诸如 两阶段提交这样的协议。如果没有这样的协议,会对分布式事务的数据完整性, 优雅降级(向下兼容),数据一致性方面带来挑战。分布式系统下肯定会出现请求处理失败的问题————连接会时不时的断掉或超时,尤其是包含多个网络请求的事务。
分布式系统中实现最终一致性通常有 三种方案:读修复,写修复,异步修复。它们都各有各的优势和劣势。我们的支付系统三种方案都用到了,分别应用于不同的场景。
异步修复涉及到通过服务器来执行数据一致性的检查,包括表扫描,lambda函数,定时任务等。另外,在支付领域通常会通过服务端到客户端的异步通知来强制保证客户端数据的一致性。异步修复和通知,可以和读写修复技术一同使用来提供第二道防线,代价就是实现复杂度上升了。
本文中我们将来讲的方案是 写修复,从客户端到服务端的每一次写请求都会去尝试修复不一致的状态。写修复需要客户端变得更智能(后面会深入介绍),需要它们不停地发送同样的请求并无需维护状态(重试状态除外)。因此客户端能够按需实现最终一致性,可以保障用户体验。实现写修复非常重要的一点是幂等。
什么是幂等?
如果一个请求支持幂等,客户端可以重复发起同样的请求,结果仍然保持一致。也就是说,多次重复请求和一次请求的结果是一样的。
幂等在包括转账在内的订单及支付系统中被广泛使用。确保一次支付请求只被处理一次是非常关键的(也被称为“ 精确一次投递”)。如果一次转账操作被调用多次,底层系统必须确保只发生一次转账。对Airbnb的支付API来说,防止向房东重复支付尤其是向客户多次收费,是十分重要的。
从设计上,幂等使得客户端通过自动重传机制对某个API发起的多次重复请求能够实现最终一致性。幂等在客户端-服务端架构中是非常常见的,这也是今天我们的分布式系统中所使用的技术。
下图从上层视角呈现了多次重复请求及理想的幂等行为的一个简单示例。不管发起多少次收费请求,用户最终只会被收一次费。
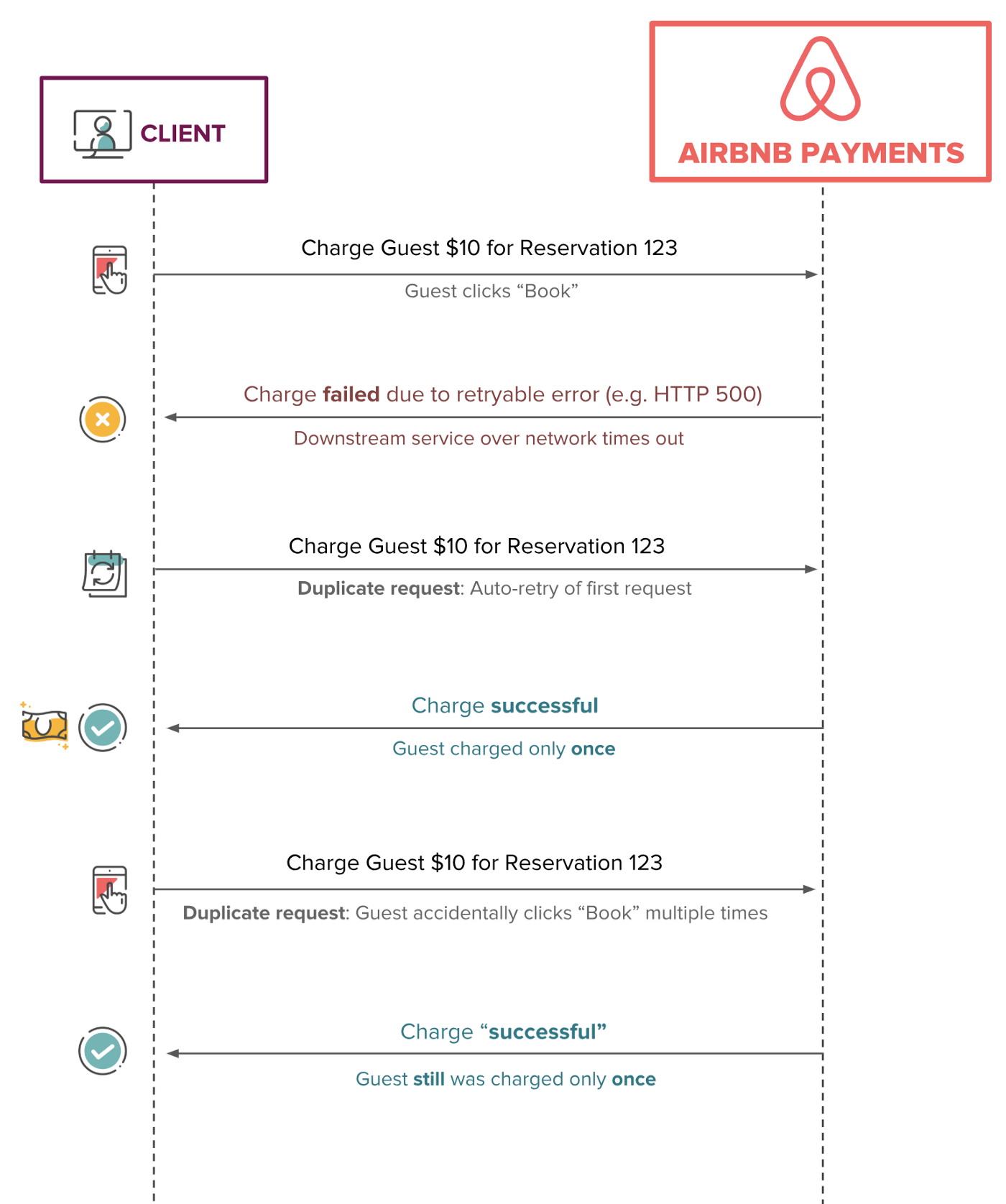
问题描述
保持我们支付系统的最终一致性是首要任务。幂等是在分布式系统中实现这一目标的理想方式。在SOA架构下会不可避免的面临新的问题。比方说,如果客户端无法处理响该如何恢复?响应丢失或客户端超时如何处理?并发场景下用户点击了两次预订如何处理?我们提出了如下几点要求:
-
我们要的不是针对特写场景的单个定制化的解决方案,我们需要一个能在Airbnb的各个SOA支付服务中通用的,可配置的幂等方案。
-
基于SOA架构的支付产品仍在不停迭代,我们不能对数据一致性有任何妥协,这会直接影响到我们的社区。
-
我们希望追求低延迟,因此构建一个独立的幂等服务是不可行的。更重要的是,这个服务还会面临本来希望它去解决的问题(译者注:我理解这里是说为了解决分布式系统的数据一致性问题,又多引入了一个新系统,反而增加了原来问题的复杂度)。
-
Airbnb正在通过SOA扩展它的工程结构,让每个开发人员都会单独处理数据完整性和最终一致性的问题是非常低效的。我们希望将开发人员从这些困扰中解放出来,让他们更关注于产品研发及快速迭代。
解决方案
我们希望能够唯一标识每个进来的请求。另外还需要在请求的生命周期内对它进行跟踪及管理。
我们实现了一个叫“Orpheus(俄耳甫斯)”的多个支付服务通用的幂等库。Orpheus是传说中的希腊神话的英雄,他的编曲和演秦能够迷倒所有生物。
之所以选择库作为实现方式,是因为它在保证低延迟的同时,还能干净地隔离开高效的生产代码与低效的系统管理代码。更高一层来看,它由以下几个简单的概念所构成:
-
将幂等key传入框架,用来标识一个幂等请求
-
始终从同一个主库的分片中读写幂等信息表
-
将不同的代码片段通过Java的lambda表达式组装在数据库事务里来保证原子性
-
失败的响应分为“可重试的“及”不可重试的“
接下来将会详细介绍一个有幂等保证的复杂的分布式系统是如何实现自愈并达成最终一致的。还会介绍这个方案所带来的一些需要注意的代价及额外的复杂度。
数据库提交最小化
幂等系统的一个关键在于能够一致地返回两个结果,成功或失败。否则错误的数据将会导致长时间的排查及错误的支付行为。由于数据库提供了ACID特性,通过数据库事务可以在保持一致性的同时,原子地写入数据。一次数据库的提交作为一个整体可以要么成功要么失败。
Orpheus的设计基于这样一个假设:所有标准的API请求都可以分成三个阶段,Pre-RPC, RPC,和Post-RPC。
RPC,也就是Remote Procedural Call(远程方法调用),指的是客户端向远程服务器发起请求,并等待对方处理完成后再继续执行。在这个支付场景中,我们用RPC来指代通过网络向下游服务发起的请求,这包括外部的支付服务以及请求银行。下面简单来说下,每个阶段会发生什么:
- Pre-RPC:将支付请求的明细记录在数据库中。
- RPC:将请求通过网络发送给外部服务并接收响应。这里可能会存在一次或多次幂等计算或者RPC(比方说,如果要重试的话会先查询下事务的状态)。
- Post-RPC:将外部服务的响应明细记录到数据库中,包括是否成功以及失败请求需要重试与否。
为了实现数据完整性,我们坚持两个基本原则:
- 在Pre-RPC和Post-RPC阶段,没有跨网络的服务调用。
- 在RPC阶段没有数据库调用。
我们的根本思想是希望避免将网络请求和DB操作混在一起。我们踩过不少坑,发现Pre-RPC和Post-RPC阶段的网络调用是很不稳定的,可能会导致连接池被快速消耗或者性能降级。简而言之,网络调用是不可靠的。因此我们将Pre-RPC和Post-RPC阶段放到由Orpheus库自己初始化的数据库事务里。
还需要注意的是一个API可能会包含多个RPC请求。Orpheus当然也支持多RPC请求,不过在本文中我们想通过一个单RPC的例子来讲明白整个处理过程。
正如下图所示,Pre-RPC和Post-RPC阶段的每次数据库提交都会 组合成一个数据库事务。这确保了原子性——整个工作单元(这里指的是Pre-RPC和Post-RPC阶段)可以作为一个单元要么成功要么失败,保持一致。这么做的目的是希望系统失败了之后可以恢复。比如说,如果多个API请求都在一长串的数据库提交执行到一半的时候失败了,就很难跟踪到每次失败发生的位置。注意到所有的网络交互,也就是RPC,都是和数据库事务明确隔离开来的。
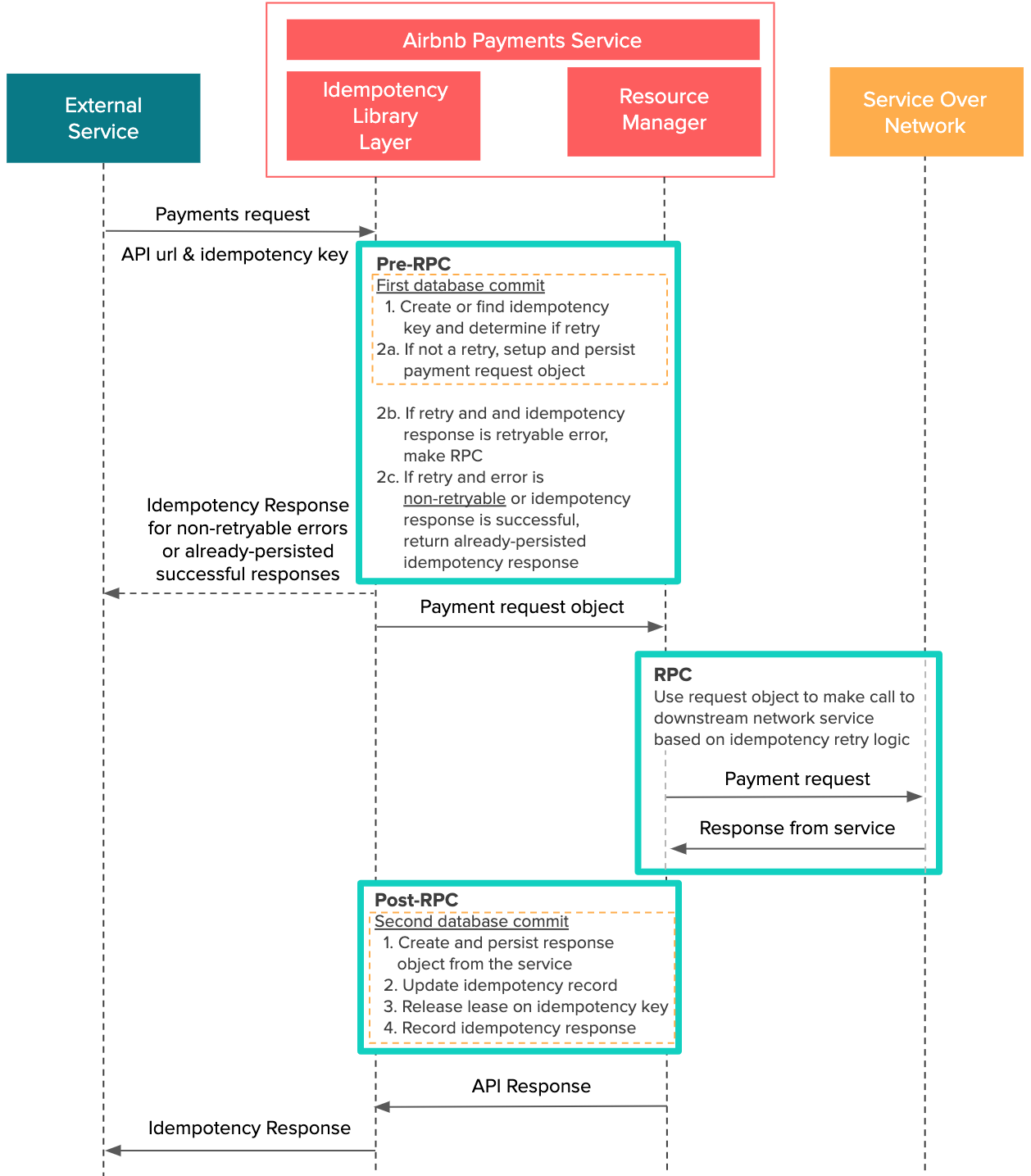
这里的数据库提交包括幂等库提交和应用层的DB提交,都在同一个代码块中。如果不注意的话,实际写出来的代码可能会看起来一团糟。我们认为不应该由业务开发人员来去调用幂等模块。
Java Lambda来救场
多亏了 Java Lambda,我们可以将多个语句无缝地整合到一个数据库事务中,而又不影响可测性和代码可读性。
下面是使用了Java lambda表达式的一个Orpheus的简单使用示例:
public Response processPayment(InitiatePaymentRequest request, UriInfo uriInfo)
throws YourCustomException {
return orpheusManager.process(
request.getIdempotencyKey(),
uriInfo,
// 1. Pre-RPC
() -> {
// Record payment request information from the request object
PaymentRequestResource paymentRequestResource = recordPaymentRequest(request);
return Optional.of(paymentRequestResource);
},
// 2. RPC
(isRetry, paymentRequest) -> {
return executePayment(paymentRequest, isRetry);
},
// 3. Post RPC - record response information to database
(isRetry, paymentResponse) -> {
return recordPaymentResponse(paymentResponse);
});
}
下面是从源码中摘录的内部实现的一个简化版:
public <R extends Object, S extends Object, A extends IdempotencyRequest> Response process(
String idempotencyKey,
UriInfo uriInfo,
SetupExecutable<A> preRpcExecutable, // Pre-RPC lambda
ProcessExecutable<R, A> rpcExecutable, // RPC lambda
PostProcessExecutable<R, S> postRpcExecutable) // Post-RPC lambda
throws YourCustomException {
try {
// Find previous request (for retries), otherwise create
IdempotencyRequest idempotencyRequest = createOrFindRequest(idempotencyKey, apiUri);
Optional<Response> responseOptional = findIdempotencyResponse(idempotencyRequest);
// Return the response for any deterministic end-states, such as
// non-retryable errors and previously successful responses
if (responseOptional.isPresent()) {
return responseOptional.get();
}
boolean isRetry = idempotencyRequest.isRetry();
A requestObject = null;
// STEP 1: Pre-RPC phase:
// Typically used to create transaction and related sub-entities
// Skipped if request is a retry
if(!isRetry) {
// Before a request is made to the external service, we record
// the request and idempotency commit in a single DB transaction
requestObject =
dbTransactionManager.execute(
tc -> {
final A preRpcResource = preRpcExecutable.execute();
updateIdempotencyResource(idempotencyKey, preRpcResource);
return preRpcResource;
});
} else {
requestObject = findRequestObject(idempotencyRequest);
}
// STEP 2: RPC phase:
// One or more network calls to the service. May include
// additional idempotency logic in the case of a retry
// Note: NO database transactions should exist in this executable
R rpcResponse = rpcExecutable.execute(isRetry, requestObject);
// STEP 3: Post-RPC phase:
// Response is recorded and idempotency information is updated,
// such as releasing the lease on the idempotency key. Again,
// all in one single DB transaction
S response = dbTransactionManager.execute(
tc -> {
final S postRpcResponse = postRpcExecutable.execute(isRetry, rpcResponse);
updateIdempotencyResource(idempotencyKey, postRpcResponse);
return postRpcResponse;
});
return serializeResponse(response);
} catch (Throwable exception) {
// If CustomException, return error code and response based on
// ‘retryable’ or ‘non-retryable’. Otherwise, classify as ‘retryable’
// and return a 500.
}
}
这么拆分也是会有一些代价的。考虑到后续会有新人加入,开发人员在设计时必须有一定前瞻性,来确保代码的可读性和可维护性。他们还需要持续评估依赖关系和传入数据的正确性。现在强制要求将API调用重构成三个小的代码块,这就限制了开发人员的编码方式。一些复杂的API调用的确是很难有效地拆分成三个执行步骤的。我们其中一个服务就实现一个有限状态机,每次状态转换都通过StatefulJ实现为一个幂等过程,这样你就可以在API调用中放心地复用幂等调用了。
异常处理——要不要重试?
使用了Orpheus框架后,服务端需要知道一个请求什么时候可以安全重试,什么时候不可以。一旦发生异常则必须认真对待————需要区分出“可重试的”及“不可重试的”。这又给开发人员增加了一层复杂性,如果他们处理时不够注意和谨慎的话,就会产生不好的结果。
比方说,如果下游服务暂时不可用了,但“可重试的”异常被错误标记为“不可重试的”。那这次请求就会永远“失败”了,后续的重试请求永远只能得到一个错误的不可重试的报错。相反地,如果“不可重试”的异常被标记为“可重试的”,则会发生重复支付,这就需要人工介入了。
通常来讲,我们认为由于网络或基础设施导致的非预期的运行时异常(5XX状态)是可重试的。我们认为这些报错只是临时的,并期望随后重发这一请求就能处理成功。
我们认为校验类的异常比如说无效的输入或者状态(比如说,退款单据是不是再发起退款的)是不可重试的(4XX状态)————我们希望后续同样的请求仍旧失败掉。我们创建了一个自定义的通用异常类来处理这类问题,它默认就是“不可重试的”,只在某些场景可以标记为“可重试的”。
确保每个请求的内容保持不变且不可修改是至关重要的,否则就破坏了幂等请求的定义了。

当然有许多边界模糊的场景还是需要谨慎处理的,比如说在不同的上下文里如何正确处理NullPointerException。举个例子,连接抖动导致的数据库返回的null值就不同于客户端请求或者第三方响应里面的null字段。
客户端的角色很关键
在篇首其实就暗示过了,在一个写修复系统里,客户端需要更智能化。如果需要和使用了Orpheus这样的幂等库的服务进行交互,客户端需要承担一些关键职责:
-
对每个新请求采用一个唯一的幂等key;重试请求使用相同的幂等key;
-
调用服务前先将幂等key持久化到DB里;
-
正确处理成功响应并随之删除(或置空)幂等key;
-
确保请求重试的过程中内容不被篡改;
-
需要根据业务需求认真设计及配置自动重传策略(使用 指数退避或 随机等待时间来避免 惊群问题)
如何选择幂等key
幂等key的选择是至关重要的————根据所选的不同key客户端可以实现请求级幂等或者实体级幂等。选择哪一种策略要视不同的业务场景而定,而请求级幂等是最直接也最常见的。
对请求级幂等而言,客户端会选择一个随机且唯一的键来确保在整个实体集层面保证幂等。比如说,如果我们希望允许某次预订可以支付多次(比如 支付少量预付款时),那就需要确保选择不同的幂等key。UUID是一个不错的使用示例。
而实体级幂等要比请求级幂等要更严格和受限得多。假设我们希望让ID1234对应的10块钱的支付单一次只能退款5元,这样我们可以从技术上控制可以进行两笔5元的退款。因此我们希望能有一个基于实体模型的确定性的幂等key来确保实体级幂等。比如说“payment-1234-refund”。这样对一笔唯一的支付单而言,它的退款请求便能实现实体级的幂等(支付单1234)。
每个API请求都有一次超时时间
如果客户端的重试策略比较激进的话,用户的多次请求就可能会触发多次重复的请求。这样就可能会在服务端上造成竞争条件,或者导致我们的社区上重复支付。为了避免这种情况,在框架的帮助下,每次API调用都会从数据库里获取的一个幂等key上的行级锁。这样这个请求便能获得一次租约或者说授权,以便继续执行。
租约对应着一个到期时间,以便应对服务器超时的情况。API请求如果获取不到响应,只能在租约到期之后才能发起重试。应用层可以根据他们的需求来设置租约到期时间和RPC超时时间。根据经验,租约到期时间应该大于RPC超时时间。
Orpheus还为每个幂等key额外提供了一个最大重试窗口,避免不断重试所导致的预期外的系统行为,保证整个网络的安全。
记录响应
我们还会将响应记录下来,以便管理及监控幂等行为。当客户端向一个已经到达确定性终态的事务发起重复请求,比如说是不可重试错误(比如说校验异常)或成功的响应,对应的响应信息其实已经持久化到数据库中了。
响应的持久化当然会造成性能损耗————客户端重试时会快速获得响应,但表大小也会随着应用的吞吐量的增长而成比例地增长。如果不够注意的话这张表会快速膨胀。定时地删除一定时间之前的记录是一个解决方案,但如果过早地删除幂等响应也会有负责影响。开发人员应当注意不要对响应体或者结构进行非向下兼容的改动。
远离备库————坚持使用主库
当使用Orpheus来读写幂等信息时,我们选择了直接操作主库。在分布式数据库中,需要在一致性和延迟时间之间进行权衡。由于我们无法容忍高延迟或者读到未提交的数据,使用主库似乎是唯一的选择。这么做就没有必要使用缓存或者备库了。如果数据库系统没有配置成强读一致性的话(我们的数据库是MySQL),使用备库的结果就正好与幂等的目的背道而驰了。
举个例子,假设有一个支付服务将幂等信息存到了备库中。客户端提交了支付服务到后端,下游也成功处理了,但是由于网络原因没有接收到响应。响应被存储到了主库中,最终会回写到备库里。然而在复制的过程中,客户端可能会向服务发起幂等重试,这个时候备库里还没有响应信息。由于响应“并不存在”(于备库中),该服务会错误地再次完成支付,这就导致了重复支付。下图解释了几秒的复制间隔是如何对Airbnb的社区产生严重的经济影响的。
复制间隔导致的重复支付
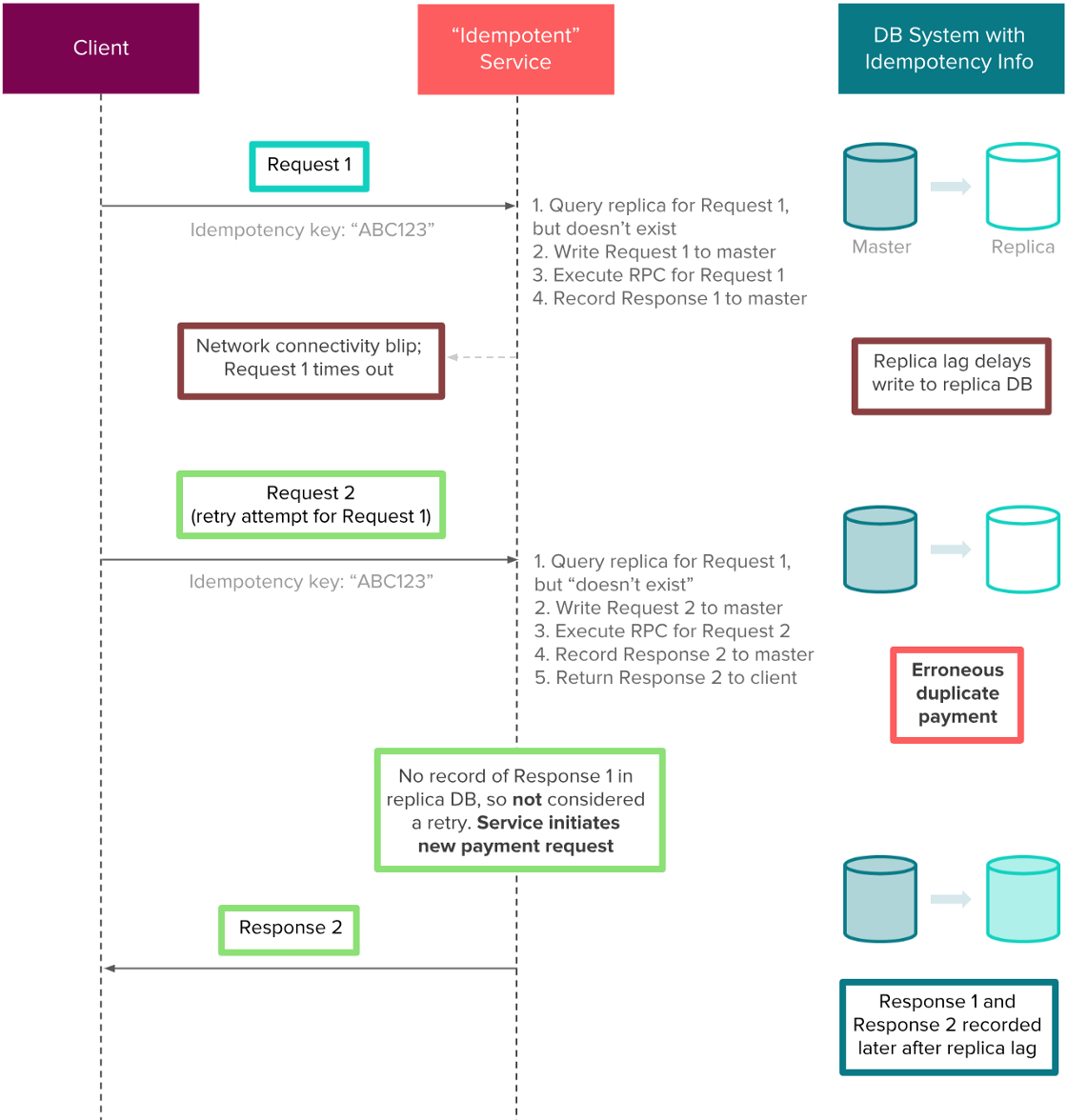
只在主库上存储幂等信息防止重复支付
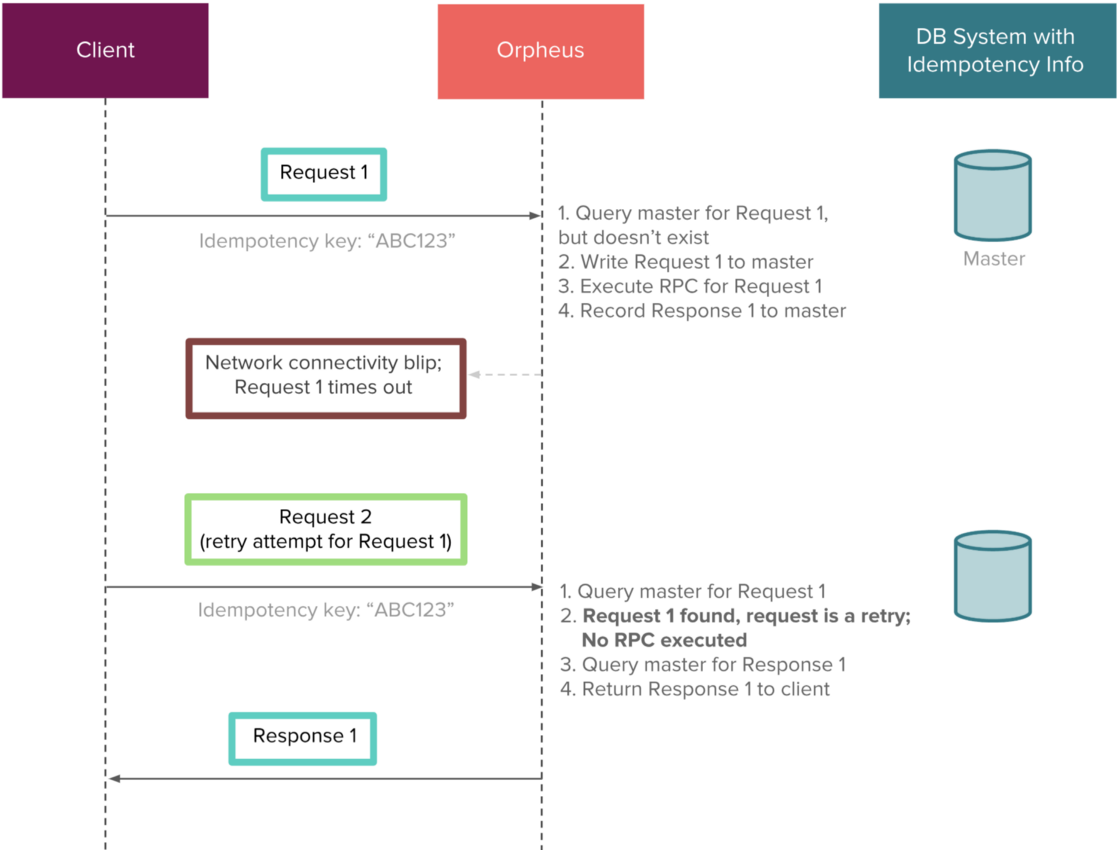
如果只使用主库来进行幂等,毫无疑问是扩展性马上就成为新的问题了。我们通过对幂等key进行分片来缓解了这一问题。我们使用的幂等key是满足高基数(high cardinality)和均匀分布的特征的,非常适合进行分片。
写在最后的话
有无数解决方案可以解决分布式系统中的一致性问题。Orpheus由于其通用性和轻量级,对我们来说是比较适用的。开发人员只需要在新建服务的时候将库导入,在应用层的概念及模型之上,会有一个隔离的抽象层来完成幂等逻辑。
然而,实现最终一致性是会增加复杂度的。客户端需要存储并处理幂等key并实现自动重试机制。开发人员需要额外的背景知识,并且在实现和调试Java lambda表达式时要格外小心。在处理异常时需要仔细斟酌。另外,由于当前版本的Orpheus仍在线上验证,我们也还在持续的进行优化:匹配重试请求,更好地支持架构调整及迁移,在RPC阶段主动限制DB访问,等等。
还有这么多问题要考虑,那目前Orpheus究竟对Airbnb的支付系统带来了多少贡献呢?自从这套框架部署上线以来,我们的支付服务在一致性方面实现了5个9,同时我们的年支付金额还翻番了(如果你想了解我们是如何大规模地测量数据完整性可以读下 这篇文章)。如果你对错综复杂的分布式支付平台和帮助用户到全世界任何地方旅游有兴趣的话, Airbnb支付团队也在招聘中!向Michel Weksler和Derek Wang致敬,感谢他们在这个项目上的领导思维及架构设计方面给予的指导!
英文原文链接