{kind=link}
[分享创造] GNE v0.1 正式发布: 4 行代码开发新闻网站通用爬虫
- - V2EXGNE ( GeneralNewsExtractor )是一个通用新闻网站正文抽取模块,输入一篇新闻网页的 HTML, 输出正文内容、标题、作者、发布时间、正文中的图片地址和正文所在的标签源代码. GNE 在提取今日头条、网易新闻、游民星空、 观察者网、凤凰网、腾讯新闻、ReadHub、新浪新闻等数百个中文新闻网站上效果非常出色,几乎能够达到 100%的准确率.
GNE ( GeneralNewsExtractor )是一个通用新闻网站正文抽取模块,输入一篇新闻网页的 HTML, 输出正文内容、标题、作者、发布时间、正文中的图片地址和正文所在的标签源代码。GNE 在提取今日头条、网易新闻、游民星空、 观察者网、凤凰网、腾讯新闻、ReadHub、新浪新闻等数百个中文新闻网站上效果非常出色,几乎能够达到 100%的准确率。
使用方式非常简单:
from gne import GeneralNewsExtractor
extractor = GeneralNewsExtractor()
html = '网站源代码'
result = extractor.extract(html)
print(result)
GNE 的输入是 经过 js 渲染以后的 HTML 代码,所以 GNE 可以配合 Selenium 或者 Pyppeteer 使用。
下图是 GNE 配合 Selenium 实现的一个 Demo:
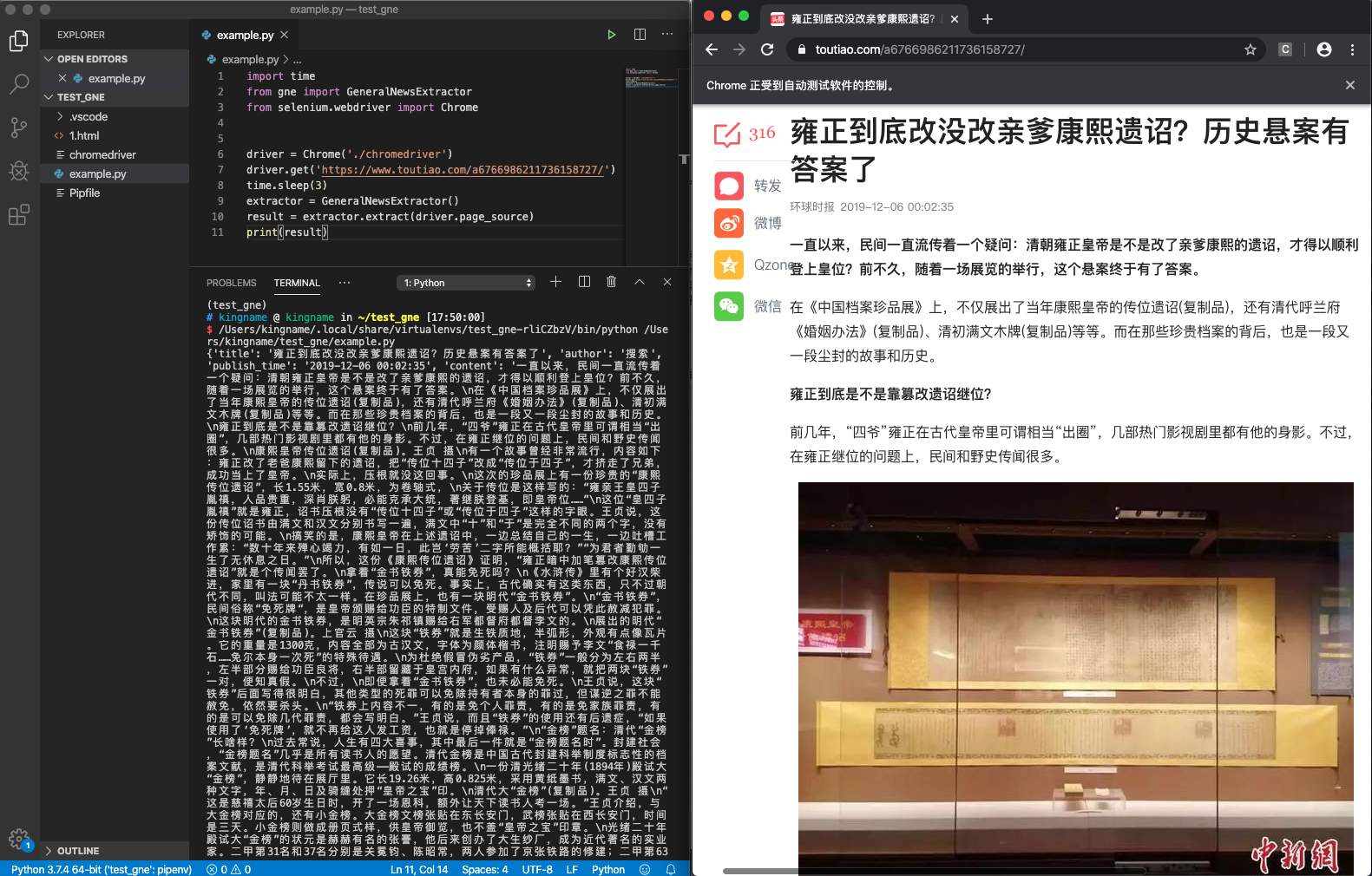
对应的代码为:
import time
from gne import GeneralNewsExtractor
from selenium.webdriver import Chrome
driver = Chrome('./chromedriver')
driver.get('https://www.toutiao.com/a6766986211736158727/')
time.sleep(3)
extractor = GeneralNewsExtractor()
result = extractor.extract(driver.page_source)
print(result)
下图是 GNE 配合 Pyppeteer 实现的 Demo:
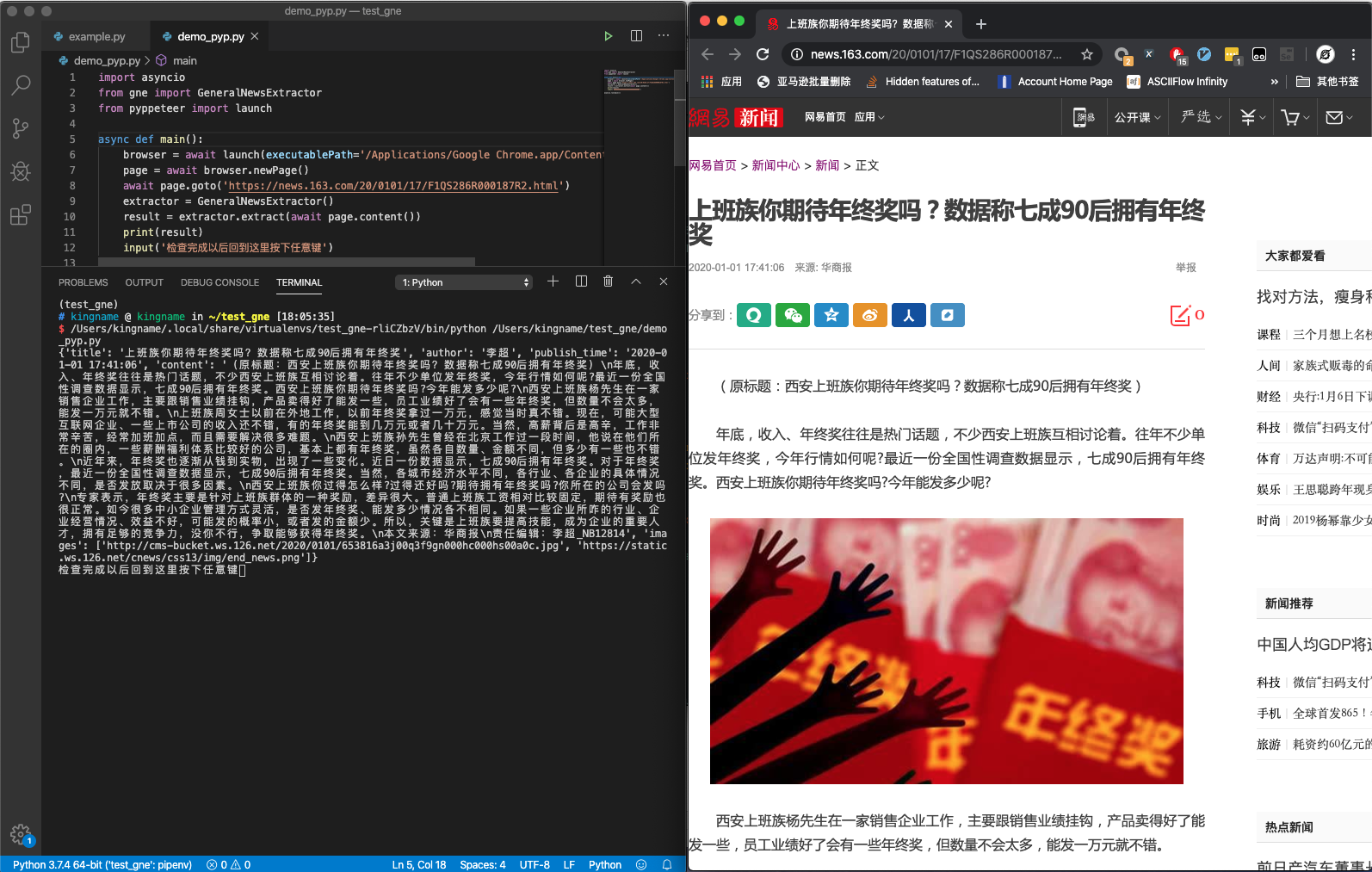
对应代码如下:
import asyncio
from gne import GeneralNewsExtractor
from pyppeteer import launch
async def main():
browser = await launch(executablePath='/Applications/Google Chrome.app/Contents/MacOS/Google Chrome')
page = await browser.newPage()
await page.goto('https://news.163.com/20/0101/17/F1QS286R000187R2.html')
extractor = GeneralNewsExtractor()
result = extractor.extract(await page.content())
print(result)
input('检查完成以后回到这里按下任意键')
asyncio.run(main())
现在你可以直接使用 pip 安装 GNE 了:
pip install gne
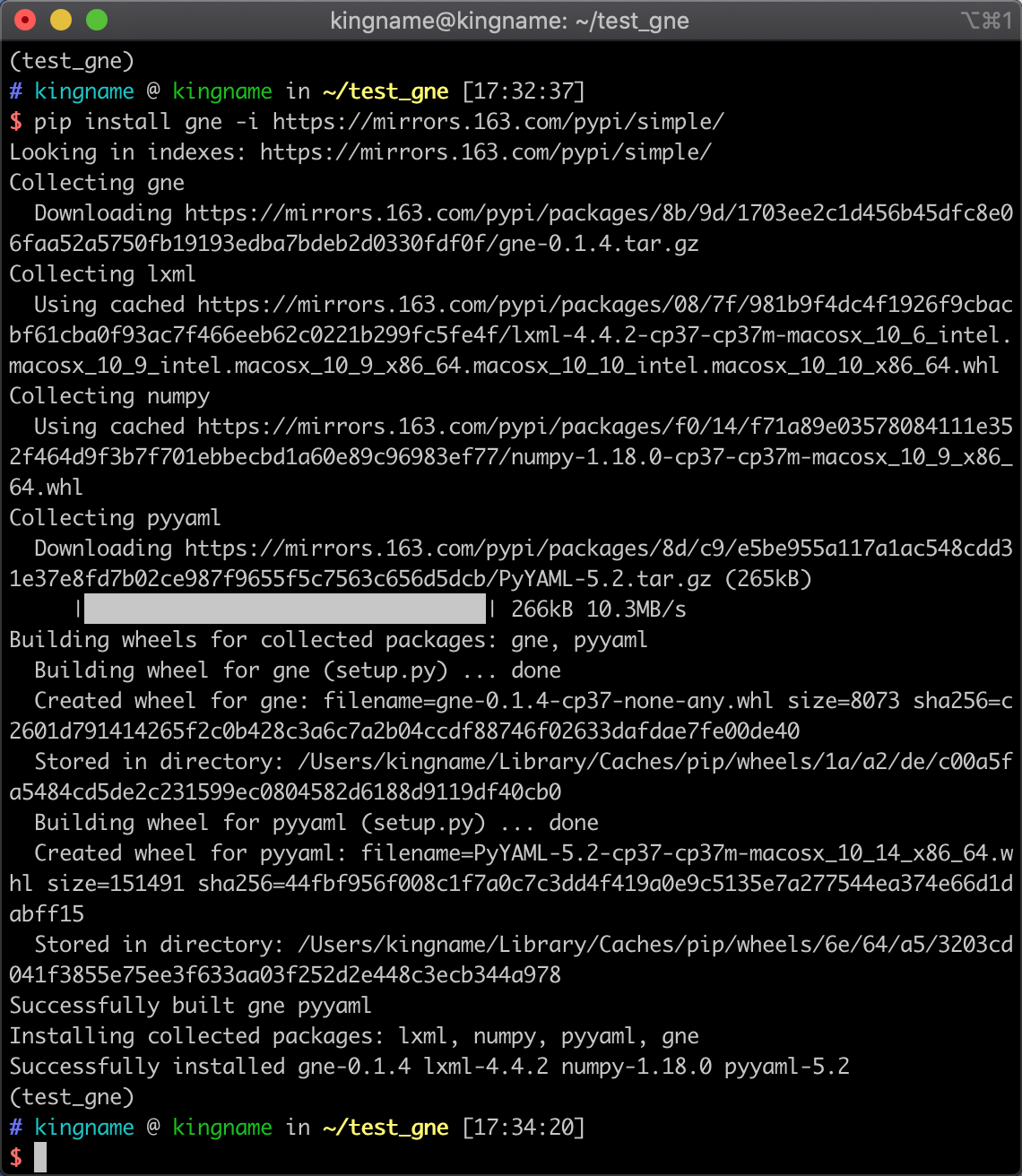
如果访问 pypi 官方源太慢,你也可以使用网易源:
pip install gne -i https://mirrors.163.com/pypi/simple/
安装过程如下图所示:
在 extract()方法只传入网页源代码,不添加任何额外参数时,GNE 返回如下字段:
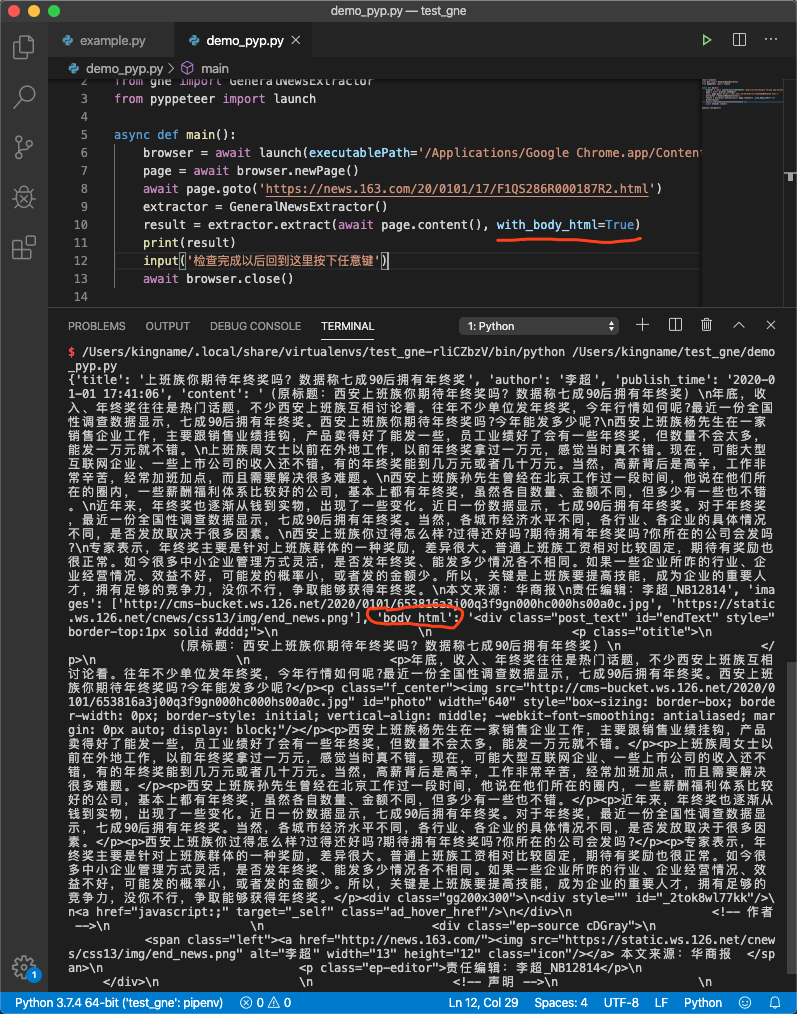
可能有些朋友希望获取新闻正文所在标签的源代码,此时可以给 extract()方法传入 with_body_html参数,设置为 True:
extractor = GeneralNewsExtractor()
extractor.extract(html, with_body_html=True)
返回数据中将会增加一个字段 body_html,它的值就是正文对应的 HTML 源代码。
运行效果如下图所示:
默认情况下,如果新闻中的图片使用的是相对路径,那么 GNE 返回的 images字段对应的值也是图片相对路径的列表。
如果你想始终让 GNE 返回绝对路径,那么你可以给 extract()方法增加 host参数,这个参数的值是图片的域名,例如:
extractor = GeneralNewsExtractor()
extractor.extract(html, host='https://www.kingname.info')
这样,如果新闻中的图片是 /images/pic.png,那么 GNE 返回时会自动把它变为 https://www.kingname.info/images/pic.png。
GNE 预定义了一组 XPath 和正则表达式用于提取新闻的标题。但某些特殊的新闻网站可能无法提取标题,此时,你可以给 extract()方法指定 title_xpath参数,用于提取新闻标题:
extractor = GeneralNewsExtractor()
extractor.extract(html, title_xpath='//title/text()')
某些新闻下面可能会存在长篇大论的评论,这些评论看起来比新闻正文“更像”正文,为了防止他们干扰新闻的提取,可以通过给 extract()方法传入 noise_node_list参数,提前把这些噪声节点移除。 noise_node_list的值是一个列表,里面是一个或多个 XPath:
extractor = GeneralNewsExtractor()
extractor.extract(html, noise_node_list=['//div[@class="comment-list"]', '//*[@style="display:none"]'])
API 中的参数 title_xpath、 host、 noise_node_list、 with_body_html除了直接写到 extract() 方法中外,还可以通过一个配置文件来设置。
请在项目的根目录创建一个文件 .gne,配置文件可以用 YAML 格式,也可以使用 JSON 格式。
title:
xpath: //title/text()
host: https://www.xxx.com
noise_node_list:
- //div[@class=\"comment-list\"]
- //*[@style=\"display:none\"]
with_body_html: true
{
"title": {
"xpath": "//title/text()"
},
"host": "https://www.xxx.com",
"noise_node_list": ["//div[@class=\"comment-list\"]",
"//*[@style=\"display:none\"]"],
"with_body_html": true
}
这两种写法是完全等价的。
配置文件与 extract() 方法的参数一样,并不是所有字段都需要提供。你可以组合填写你需要的字段。
如果一个参数,既在 extract() 方法中,又在 .gne 配置文件中,但值不一样,那么 extract() 方法中的这个参数的优先级更高。
GNE 不是爬虫,它的项目名称 General News Extractor 表示通用新闻抽取器。它的输入是 HTML,输出是一个包含新闻标题,新闻正文,作者,发布时间的字典。你需要自行设法获取目标网页的 HTML。
GNE 现在不会,将来也不会提供请求网页的功能。
GNE 不支持翻页。因为 GNE 不会提供网页请求的功能,所以你需要自行获取每一页的 HTML,并分别传递给 GNE。
不小于 Python 3.6.0
GNE 是基于 HTML 来提取正文的,所以传入的 HTML 一定要是经过 JavaScript 渲染以后的 HTML。而 requests 和 Scrapy 获取的只是 JavaScript 渲染之前的源代码,所以无法正确提取。
另外,有一些网页,例如今日头条,它的新闻正文实际上是以 JSON 格式直接写在网页源代码的,当页面在浏览器上面打开的时候,JavaScript 把源代码里面的正文解析为 HTML。这种情况下,你在 Chrome 上面就看不到 Ajax 请求。
所以建议你使用 Puppeteer/Pyppeteer/Selenium 之类的工具获取经过渲染的 HTML 再传入 GNE。
不支持。
GNE 官方文档: https://generalnewsextractor.readthedocs.io/
GNE 的项目源代码在: https://github.com/kingname/GeneralNewsExtractor。
