HDFS+Clickhouse+Spark:从0到1实现一款轻量级大数据分析系统
- - InfoQ推荐导语 | 在产品精细化运营时代,经常会遇到产品增长问题:比如指标涨跌原因分析、版本迭代效果分析、运营活动效果分析等. 这一类分析问题高频且具有较高时效性要求,然而在人力资源紧张情况,传统的数据分析模式难以满足. 本文尝试从0到1实现一款轻量级大数据分析系统——MVP,以解决上述痛点问题. 文章作者:数据熊(笔名),腾讯云大数据分析工程师.
导语 | 在产品精细化运营时代,经常会遇到产品增长问题:比如指标涨跌原因分析、版本迭代效果分析、运营活动效果分析等。这一类分析问题高频且具有较高时效性要求,然而在人力资源紧张情况,传统的数据分析模式难以满足。本文尝试从0到1实现一款轻量级大数据分析系统——MVP,以解决上述痛点问题。文章作者:数据熊(笔名),腾讯云大数据分析工程师。
在产品矩阵业务中,通过仪表盘可以快速发现增长中遇到的问题。然而,如何快速洞悉问题背后的原因,是一个高频且复杂的数据分析诉求。
如果数据分析师通过人工计算分析,往往会占用0.5-1天时间才能找到原因。因此,人工计算分析方式,占用人力大,且数据分析效率低。
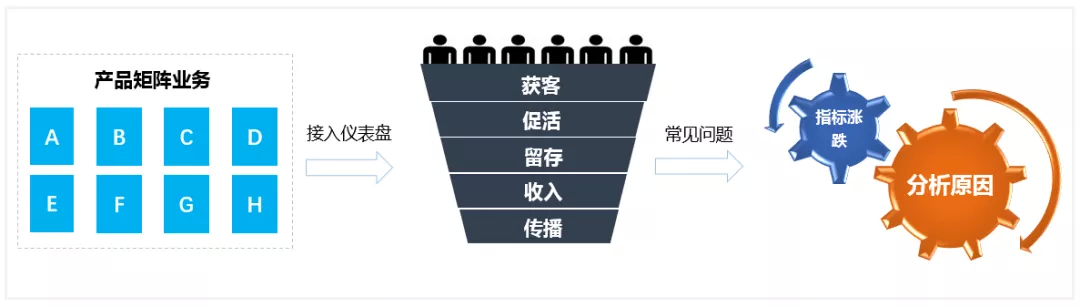
另外,产品版本迭代与业务运营活动,也需要对新版本、新功能、新活动进行快速数据分析,已验证效果。因此,在产品矩阵业务精细化运营中,存在大量的数据分析诉求,且需要快速完成。
在传统的数据分析模式下,对于每个需求,一般需要经历3-5天才能解决问题。除此之外,该模式还需要大量数据分析师对接需求。因此,在数据分析师人力紧缺情况下,该模式无法满足产品增长的数据分析诉求。

在传统数据分析模式失效情况下,急需开拓新的数据分析模式,以快速满足产品增长的数据分析诉求。
为此,笔者和项目小团队从0到1实现一款轻量级大数据分析系统——MVP,希望通过MVP数据分析,驱动产品从"Minimum Viable Product" to “Most Valuable Product”。
除此之外,通过MVP数据分析系统,一方面希望提升数据分析效率;另一方面希望节省数据分析人力。
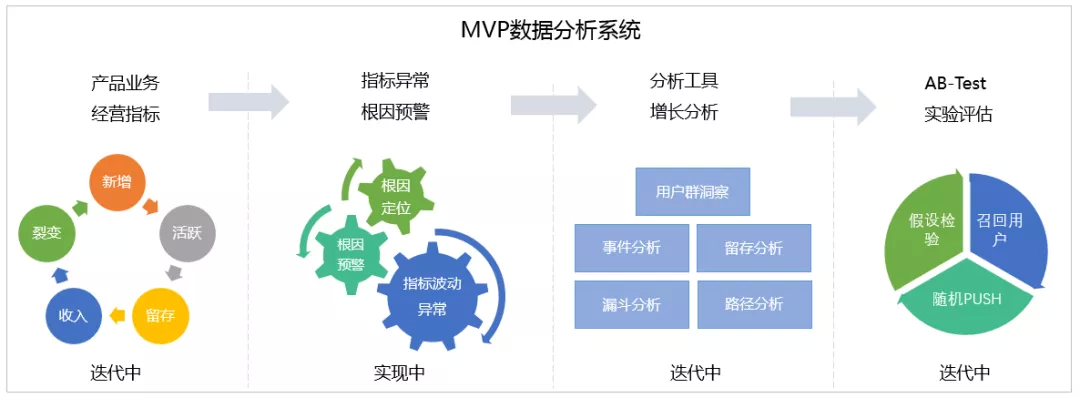
MVP数据分析系统分为四个模块,在产品业务-经营指标模块,基于AARRR模型对产品增长指标分析,分析产品增长北极星指标;在指标异常-根因预警模块,对增长指标异动进行监控,并提供根因线索;在分析工具-增长分析模块,对用户行为进行深入分析,洞悉用户行为;在AB-Test实验评估模块,对业务决策方案进行实验,评估业务决策的合理性。通过四个模块,实现数据分析驱动产品精细化运营。
一款轻量级大数据分析系统,至少需要从数据建模、技术选型、页面交互三方面实现。数据建模如水流,贯穿整个数据分析系统;技术选型是基础设施,支撑整个系统高效运转;页面交互是面向用户,用数据说话,对业务增长进行数据赋能。
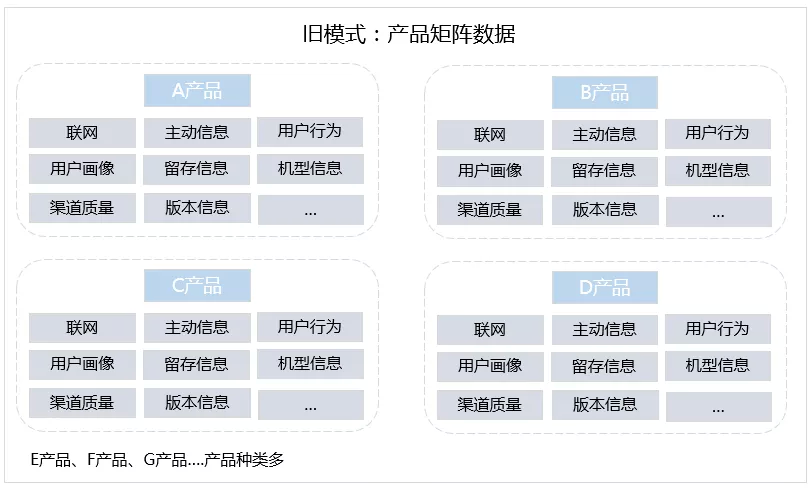
在开发MVP之前,由于历史原因,现有的产品矩阵中产品与产品之间,存在数据建设分散、数据开发重复、数据隔离等问题,一个用户会存在多条信息记录。
这种数据格局,不仅会导致计算、存储、人力资源的浪费,更严重的是会很大程度影响上层数据应用的效率。因此,旧的数据模式行不通,需要开拓新的数据模式。
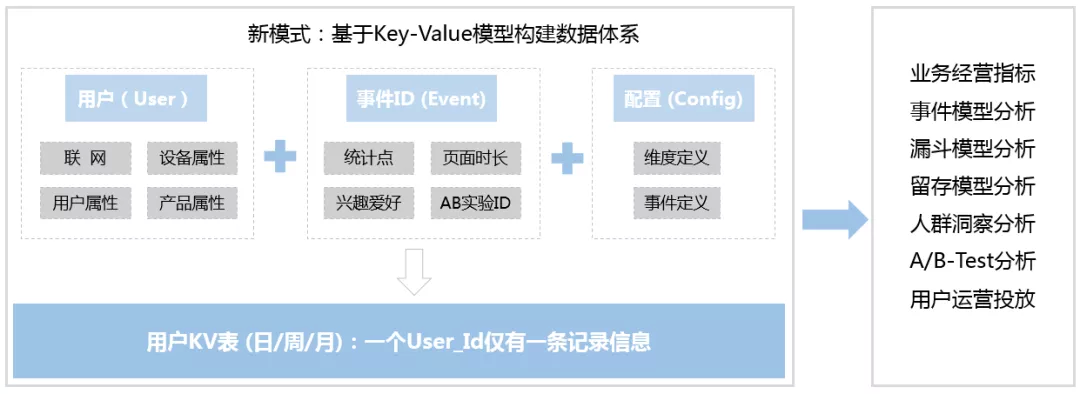
MVP数据分析系统底层数据建设,一方面基于“用户(User)+事件ID(Event)+配置(Config)”思路,对产品数据信息进行高度抽象整合,收敛产品矩阵业务数据;另一方面,基于Key-Value模型,生成用户大宽表,一个User_Id仅有一条记录信息。
在日常产品数据可视化中,通常会想到使用MySQL进行页面交互式数据分析,但是MySQL数据库承载数据能力在百万级,适合对结果型数据进行分析,对于上亿级数据是无能为力。
在复杂的数据分析场景中,通常需要基于用户画像与用户行为,对用户进行OLAP多维自由交叉组合分析。因此,对于百万级以上的产品业务,使用MySQL是无法满足OLAP实时分析,需要尝试新的技术选型。
为了实现实时OLAP分析,对业界的大数据分析平台的技术方案我们进行了调研比较。业界存储引擎主要是HDFS与HBASE,计算引擎使用比较多的是Impala,Druid,Clickhouse,Spark。Druid系统维护成本高,无Join能力,且语法应用相对复杂。
从计算速度角度,Clickhouse比Presto快2倍+,比Impala快3倍+,比SparkSql快约4倍,计算性能比较如下。
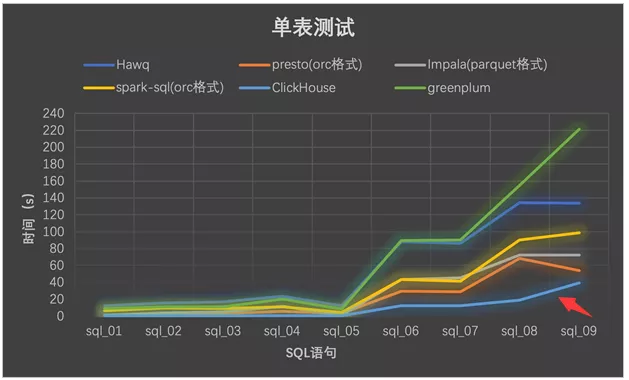
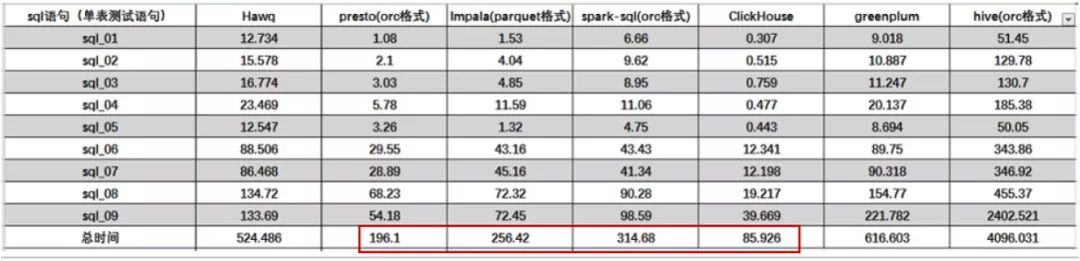
实测数据,对2.2亿+条1.79GB记录数据,进行单表聚合0.095s,分析速度18.95GB/s。
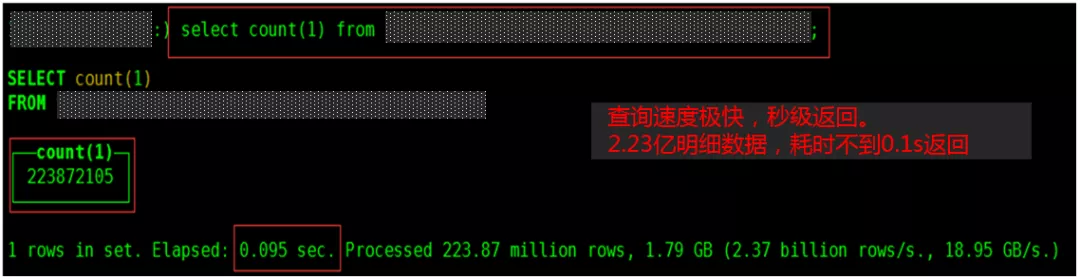
和Impala相比,Clickhouse可以通过JDBC直接导入,数据导入成本低,Clickhouse系统维护成本相对低。另外,Clickhouse语法简单,易用性很强,对页面开发友好,可以快速开发出可视化页面。
基于上面这些因素,我们采用HDFS+Clickhouse+Spark技术方案。在这里,使用Spark补齐Clickhouse无法进行大规模Join操作短板,比如处理大规模复杂的关联分析任务。
另外,Spark可以无缝访问HDFS中Hive表数据,无需重新导数据,应用效率高。使用HDFS存储历史全量用户标签与用户行为数据(占比约80%),使用Clickhouse存储近期用户标签与用户行为数据(占比20%)。
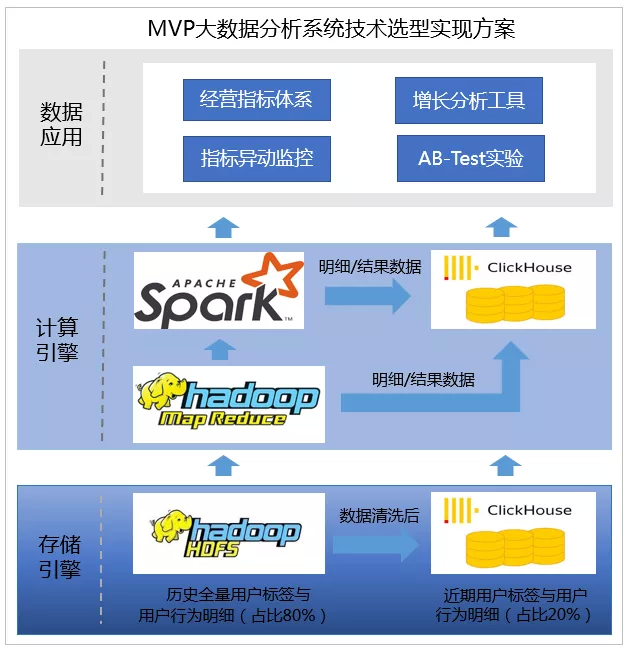
MVP页面交互形式,80%数据分析诉求是可以直接通过页面实时分析完成,剩下约20%复杂分析任务,是通过提交任务式分析完成。
页面实时分析秒级返回分析结果,提交任务式分析需要5-15分钟返回结果。经营指标体系、事件模型分析、漏斗模型分析、留存模型分析等,是通过页面实时分析完成,用户人群画像洞察、用户兴趣偏好洞察是通过提交任务式分析完成。
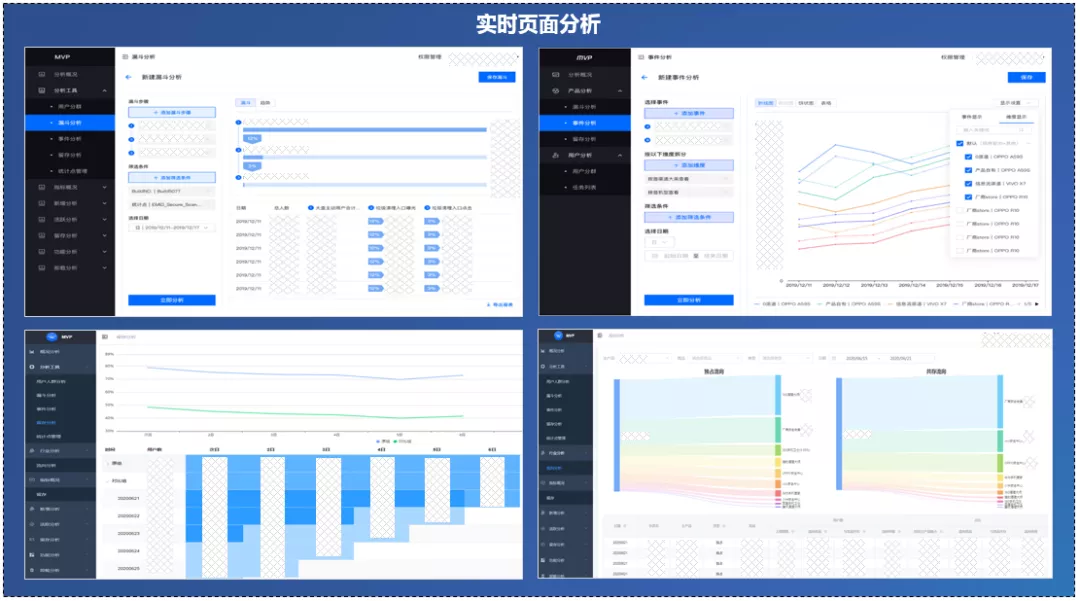
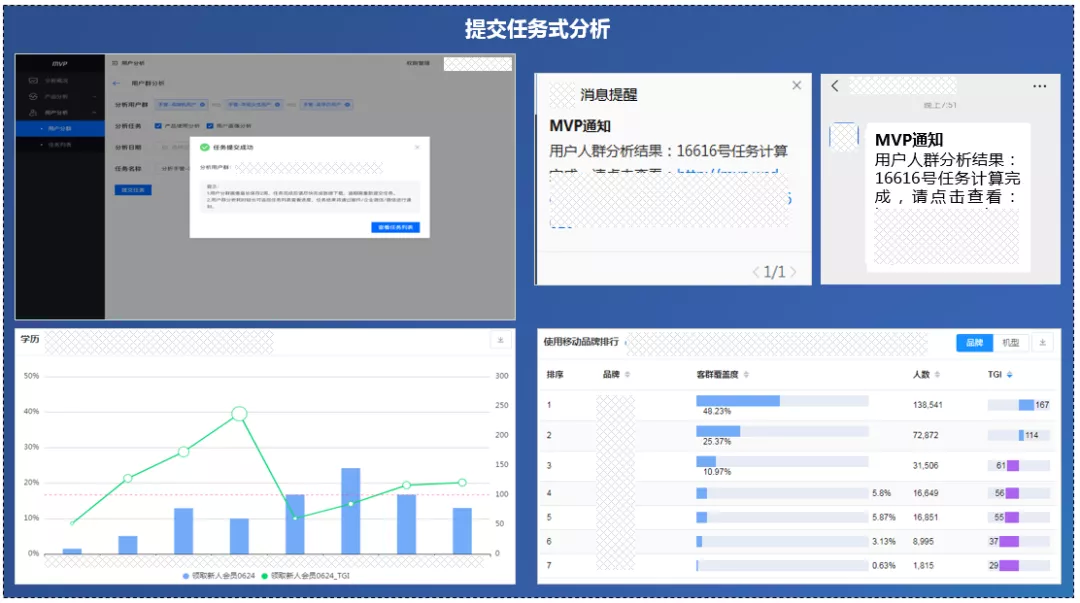
按照传统数据分析模式,根据“提出需求->需求评审->写需求单->数据分析->输出结果”的规范流程,数据诉求需要经历3-5天才能解决问题,通过MVP系统可以快速完成数据分析诉求,大大缩短工期,对分析效率提升明显。目前MVP数据分析系统已经在内部使用,近期,使用MVP进行数据分析任务数达到1500+,高峰突破两千次。
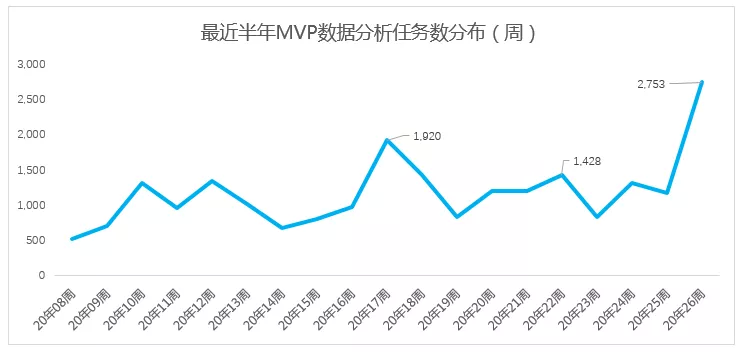
从“人工数据分析 -> 工具化数据分析”的转变,对数据分析效率提升明显,更有利于数据驱动产品精细化运营。
本文尝试介绍从0到1实现一款轻量级大数据分析系统——MVP。目前MVP数据分析系统已经在内部使用,对于提升数据分析效率明显,为数据驱动产品业务增长赋能。同时,节省了数据分析师的人力投入。后期,基于产品矩阵业务,在完善现有模块情况下,还将对各个增长工具进行进一步打磨,提升MVP使用体验。
MVP作为内部系统,目前为部门在移动数据分析中节约了大量的时间成本,并沉淀了丰富的互联网分析模板与工具。在部门服务行业客户过程中,我们发现MVP所代表的移动数据分析解决方案,是目前传统产业数字化转型同样需要的必备工具。
为此,后续我们利用轻量级数据平台—— 先悉 作为数据底座,解决了MVP对外部署的底层平台问题,开发了可单独私有化交付给行业客户使用的MVP toB版本,帮助行业客户通过实时用户行为分析、画像洞察为驱动,优化运营策略。
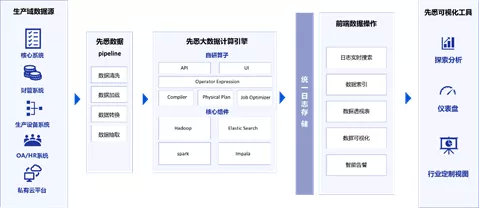
先悉数据平台是一款轻量级的大数据平台产品, 有部署性价比高、运维便利、可私有化等特点,能够以“小而美”的方式满足中小规模项目的大数据应用落地 。在具体项目实践中,先悉数据平台+MVP形成了一套优势互补的组合,目前已经开始为行业客户提供“开箱即用”的移动分析服务。
先悉功能简介:
先悉数据平台咨询/商务合作:[email protected]
参考文章:
[1] https://zhuanlan.zhihu.com/p/54907288
[2] https://clickhouse.tech/docs/en/sql-reference/statements/create/
本文转载自公众号云加社区(ID:QcloudCommunity)。
原文链接: