细说 用户画像
- - 神刀安全网对于互联网从业者,经常会提到一个词——用户画像. 作为一名刚主要做用户画像DMP的数据PM,工作中总是会被需求方问到——. 我要查看XXX的用户画像 或是 能否能够XXXX类用户的画像. 抑或是有别的产品会问到:你们是怎么做用户画像的. 然而在沟通的过程中,我发现,不同的人对用户画像的理解差异还是非常大的.
用户画像承载了两个业务目标:一是如何准确的了解现有用户;二是如何在茫茫人海中通过广告营销获取类似画像特征的新用户。比如在了解用户的基础上明确产品定位,“投其所好”;获取一个新用户/新订单;售前的精准营销、售中的个性化推荐匹配,以及售后的增值服务等。
著名广告大师约翰•沃纳梅克提出:我知道我的广告费有一半浪费了,但遗憾的是,我不知道是哪一半被浪费了。这句话深刻的道出了广告营销海量投放下面临的几个问题:
而如果在精准营销大行其道的今天通过筛选标签对特定属性的用户推送针对性的内容,则可以大幅提升CTR和变现效果,同时还能降低广告、运营成本,总结起来就是:在对的时间,向对的客户,通过对的渠道,推荐对的产品。
比如 DSP、流失预测、沉默用户分析(代金券发放)、非活跃用户(短信\push召回)、
忠诚用户(极速退款、VIP客服)等
用户画像时下一个比较重要的场景是搜索推荐,把画像数据做特征使用,可以有效提升 CTR,结合搜索、query意图识别与推荐,常见的方向有:
这个方向在电商、金融、初创公司是很重要的,如何避免或者降低羊毛党、黄牛、欺诈对业务的风险和用户损失,保障正常用户的利益,是个永恒的话题。比如可以利用用户画像对个人及企业级信用评分进而做到欺诈识别,现在 芝麻信用 就是个很好的例子,利用它做用户征信可以有效提升用户体验,降低企业成本与风险,比如共享单车免押金,酒店免押金预订后付费等。
产品精细化运营,个性化分析支持,这个就无需赘言了,比较广泛的应用场景,主要用数据解决 what 和 why 层面的事情。
总的来说,在用户画像是精细化运营、数据化运营的产物。而大数据的本质是消除不确定性,结合大数据我们可以更加精准的分析了解用户特征/用户行为,以便更好更多地服务于大多数用户,比如发送较少的优惠券和补贴,同时还能做到反作弊避免薅羊毛行为。
从用户角度而言,用户画像可以应用于用户的整个服务生命周期:
从产品角度而言,用户画像可以应用于产品的生命周期:
用户画像是根据用户社会属性、生活习惯和消费行为等信息/数据而抽象出的一个标签化的用户模型。
构建用户画像的核心工作即是给用户贴“标签”——用数据来描述人的行为和特征,用通过对用户信息分析而来的高度精炼的特征标识(标签)从不同的维度来表达一个人,是对现实世界中用户的数学建模,是数据策略的基石。从数据结构角度而言,用户画像是一个(用户,标签列表)二元组。
截止2016年5月31日,三大运营商用户数分别为 8.5亿、2.6亿、2.0亿,上月底微信 MAU 已达 9.5亿,从这些数字来看,中国的互联网普及率还是很高的,但在大数据统计分析、用户画像等场景中,经常会面临的一个问题是怎样识别和标示唯一用户?像微信、QQ这种天然闭环的业务相对容易,但像信息流、分类信息类非闭环业务怎么办?用户不需要登录即可浏览信息使用服务,比如头条网易新闻客户端、百度搜索引擎、58同城等,这样当用户有跨屏行为、跨业务客户端场景时,很难持续的追踪、准确的刻画一个用户的全貌。从技术上而言,cookie 这种技术在移动互联网时代追踪用户是极其不稳定和准确的,另外用户标识还可能有如下形式存在:IMEI、Token、IDFA、CellNO、UserID、IP、MAC,如何将这些原始ID聚集关联到真实用户上,将之和多渠道信息、多渠道的产品打通,这其中横跨了数据治理、数据整合、业务打通等几个难点。
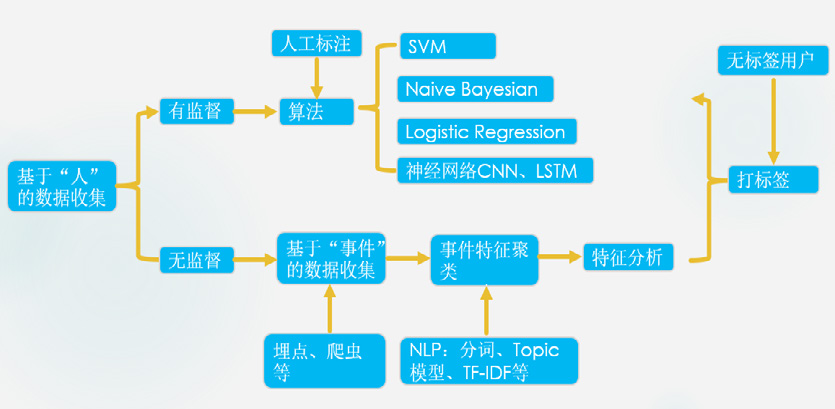
用户标签是表达人的基本属性、行为倾向、兴趣偏好等某一个维度的数据标识,它是一种相关性很强的关键字,可以简洁的描述和分类人群。比如好人和坏人、90后80后,星座、白领等。具体流程一般是从纷乱复杂、琐碎的用户行为流(日志)中挖掘用户在一段时间内比较稳定的特征,即给用户打上标签,标签的确定,一般是先人工筛选小样本规则,进行验证标注,规则合理后,在通过算法扩展。最后是评估画像的好坏:小样本的真实验证;A/B Test; 在实际的case 中迭代验证,这点从技术角度而言会有些挑战,比如怎么保证准确率和覆盖率。
3.2.1.1 属性标签:
比如自然属性标签里的性别、年龄、星座等,社会属性里的职业、社交、出生地、电话号码等
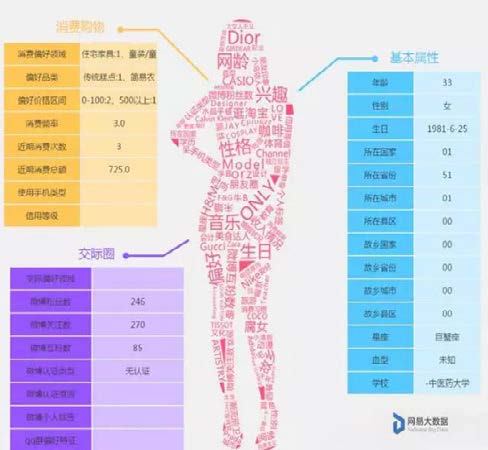
这块有一定的门槛,因为不再是基于事件行为的事实统计了,需要一定的挖掘算法做预测,咱们以性别为例:
性别属于个人隐私,不是每个用户都愿意填写,而且出于保护自己或者其它目的,填了也不一定是真实的,此时你想给用户打上性别标签,就需要用到机器学习相关的算法了,而且需要对准确性和覆盖率负责。

3.2.1.2 事实标签
比如购买行为、位置包括常驻地出差地等、使用设备、社交属性等,这类一般都可以直接从日志中直接提取,加以简单的聚类算法辅助即可。
3.2.1.3 营销标签
这块比较偏业务属性了,往往带有明确的业务目标建模而成的,比如LTV用户价值、活跃度、忠诚度、兴趣爱好、白领、高奢、有房一族、购买偏好等。
3.2.1.4 预测标签
比如之前提到的性别,其实在大部分场景下也属于一个预测标签,一般而言,我们需要一定的数据挖掘算法,集合用户日志提取APP特征、事件特征、浏览内容特征,对非结构化数据来说,通常要经历“分词”、“过滤”和“特征提取”三个步骤。另外一块是数据建模,选用合适的算法训练数据,比如到底是分类还是聚类,朴素贝叶斯,逻辑回归,SVM,神经网络哪一个合适?在模型的优化过程中,调参优化是非常重要的一步,在调参优化过程中我们通常会遇到过拟合,样本不均等情况,从整个业界来看,整体模型也差不太多,能拉开差距的基本还是对数据的理解和数据处理上,再举个例子:咱们要打个大学生标签,那么有哪些思路?基于 LBS 数据?APP 关联数据比如特殊APP/四六级、考研、超级课程表?
3.2.1.5 技术方案
技术这块涉及到存储和计算,一般根据公司的业务体系来设计,存储有HDFS,HBASE,ES等等,计算有 HIVE、Storm、Kylin、Spark 等,标签的更新频率分场景:每日更新,每周、每月更新。
标签数据的验证也是个比较耗资源的事情:
不同的标签是对用户不同侧面的量化描述,而一系列的标签集合则构成了标签体系,比如用户画像,商家画像、产品画像。
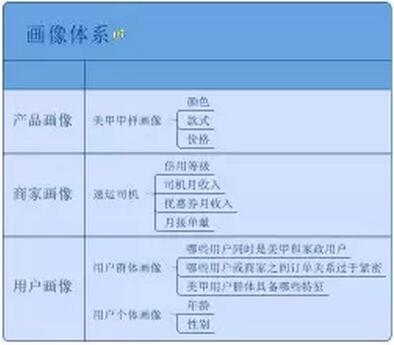
标签体系的构建策略可以按扁平结构或层级结构来分比如下图两者都有体现:
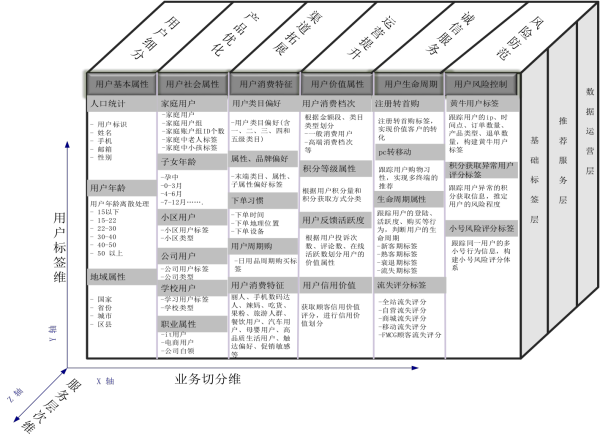
标签体系也叫群体画像,群体画像与个体画像两者都是对人的描述,但群体画像归纳的是人群所呈现出的共性,而非多样性特征。比如想得到美甲用户群体的画像,就需要用一定的方法寻找他们的共性,除了统计手段可实现外,更简单的办法是把这些个体的年龄\性别\职业\收入等标签作为数据挖掘聚类算法的输入,
聚成较少的几类比如2类或3类,如果某个类别的用户所占比例较高,那么这个类别的群体特征就代表了整个群体的画像,画像标签可能是:女性\年龄25-30岁\自由职业\收入万元以上。
在标签的构建手段上,不仅是数据挖掘,根据业务经验的判断往往更行之有效简单易行:业务经验结合大数据分析为主勾画的人群,此类画像由于跟业务紧密相关,更多的是通过业务人员提供的经验来描述用户偏好。比如:根据业务人员的经验,基于司机路程偏移、时薪和当天服务用户数等等,建立多层综合指标体系,从而对用户的欺诈可能性进行分级,生成司机信用评级的画像。
画像标签构建涉及到大数据采集、存储、建模、计算、可视化展现全链路,除了对算法有要求,对工程架构能力还是有比较高的要求的。
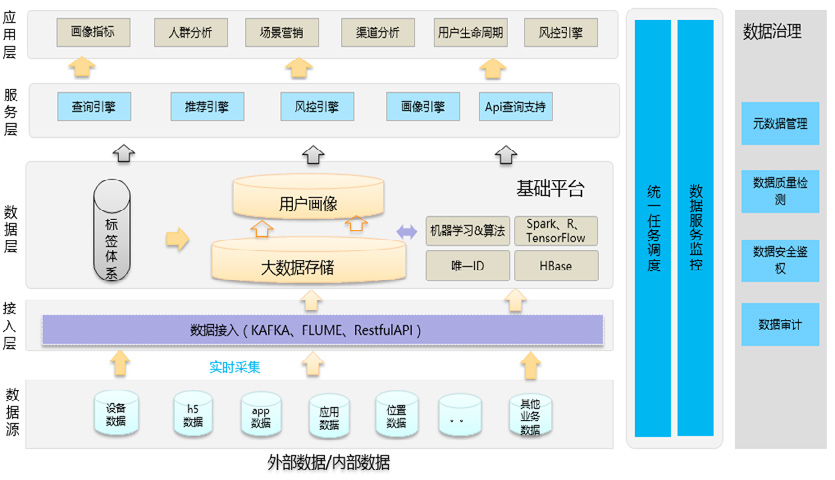
我们不能靠层出不穷的业务需求来驱动,反之,我们要总结过往经验和潜在的画像标签需求,形成一个标签体系形成一个动态的、完整的、闭环自我优化的画像系统,并将其包装成服务升级为策略并推广到平台的各个应用中去。比如平台需要支持业务数据接入、应用场景落地、画像搜索、人群分析、人群定向、API、数据反馈与闭环。
本文比较系统性的从业务需求与场景、概念原理、技术方案、架构与难点对用户画像比较全面的进行了阐述,但整体偏理论,希望以后有机会做实践方向的深入分享。
注:本文部分图片、思路来自于各大技术大会上的分享,由于作者、地址过于分散且没有存档,在此一并表示感谢,而不再一一列举。
__END__