Original article translated from Chinese, written by edmond, link is https://zhuanlan.zhihu.com/p/1930893902623245386
Translation helped with Claude and edited by myself.
I expect this article to become the most revolutionary technical discussion on self-control in the Chinese internet (as of 2025), bar none.
Perhaps this goal seems a bit audacious, but dear readers, if you have reservations about this claim, please allow me to invite you to quickly scroll through and get a feel for the style and content of this article - perhaps it might slightly increase your confidence :)
The core idea I want to convey in this article is: The problem of self-control need not only be a psychological or physiological problem - perhaps it can also be an engineering problem that can be solved using mathematics and physics.
— Based on the above concept, there exists such a possibility: A person can impose lasting and profound constraints on their own behavior through just a few abstract yet ingenious thought experiments, without any external deadlines, environmental constraints, or even any external supervision - even to the extent of changing the long-term stable state of their entire life.
(Of course, it must be specially noted that even the most powerful methodology can only partially solve behavioral problems. Many severe neurological and pathological issues still need to be addressed through professional medical channels.)
To validate this idea, as someone who has been severely troubled by ADHD and self-control issues since childhood, I spent over a decade from elementary school through my doctoral studies, experiencing countless trials and errors, thinking and verification, gradually exploring the two generations of self-control techniques that this article will introduce.
They once helped me transform from someone who struggled long-term and couldn't focus for even an hour, to being able to continuously study at home all day for several months without external pressure, with my life in well-ordered condition. The exploration process of these two generations of techniques was also an interesting and winding journey of continuous trial and iteration regarding the phenomenon of "self-control."
Therefore, I have always considered writing this article as a mission that must be completed: I hope to offer them as a gift to those who, like my former self, are tormented by ADHD and self-control barriers. Dear strangers, I hope it can help you, and others who are suffering, even if only to solve a little bit of the troubles brought by self-control problems.
Next, I will slowly tell you about these two sets of methods. They are respectively called CTDP (Chained Time-Delay Protocol) and RSIP (Recursive Stabilization Iteration Protocol). The thinking behind these two methods is completely different from the commonly discussed concepts of "putting down your phone," "making plans," "goal decomposition," "reward and punishment mechanisms," "delayed gratification," "intrinsic motivation," "habit tracking," and countless other clichéd discussions.
— What I want to do is to abstract the underlying mathematical and physical mechanisms from daily behavior, attempting to start from first principles, to solve as elegantly as possible (and partially) the age-old self-control problems of procrastination, difficulty starting, giving up midway, and low states that have plagued humanity for hundreds of years.
Of course, in this process, I will introduce some basic mathematical concepts, which may require some foundation in college-level mathematics to fully understand. But rest assured, I will try my best to use accessible popular science language, explaining concepts in a qualitative and semi-quantitative manner (quantitative analysis is also unrealistic for this topic). Additionally, to allow more friends with attention barriers like me to read through smoothly, this article will also adopt a more ADHD-friendly colloquial writing style, with illustrations interspersed, and organized using numbered paragraphs.
Finally, a small reminder: During the reading process, you will likely have various questions (for example, when reading about the Sacred Seat Principle, you might wonder "what if I cheat" or "what if I just refuse to sit down"). Please don't be anxious - usually the next section will answer these questions. And many of the limitations of the first-generation method will also be discussed and resolved in the second-generation method introduced after Section 13. In short, please read slowly and don't rush :)
CTDP Chained Time-Delay Protocol
Before the formal discussion, let's consider a most common scenario:
Suppose it's now 7 PM, you just finished dinner, sitting at your desk with homework to complete or a paper you want to read. At the same time, your phone screen lights up, and you catch a glimpse of an interesting notification on Xiaohongshu (Chinese social media). At this moment, two choices are presented to you:
- Play with your phone: You'll get immediate relaxation and happiness, however, this seems likely to ruin your study plan for tonight, and may later produce anxiety and regret;
- Go study: You'll face immediate boredom and fatigue, however, this will alleviate your recent task pressure and help with your studies.
And faced with this choice, almost everyone with poor self-control will tend to scroll through videos all night, then regret it immensely. Why is this exactly?
This question is the most classic toy model under the self-control problem. Regarding it, people have proposed various discussions - the so-called willpower model, dopamine, reward and punishment mechanisms, goal decomposition, delayed gratification, environmental control, psychological suggestion, identity recognition, to-do lists, and countless academic concepts, empirical rules, and folk remedies.
However, in this article, I will abandon all the above commonplace, vague concepts, and instead use a simple mathematical model to explain.
2
This is the first assertion of this article: When people face any choice, the true inclination toward a certain behavior can necessarily be expressed as the product of that behavior's future value function $V(\tau)$ and the weighted discount function $W(\tau)$ , integrated from the current moment ( $\tau=0$ ) to infinity:
I=∫0∞V(τ)⋅W(τ)dτI=\int_0^{\infty}V(\tau)\cdot W(\tau)d\tauI=∫0∞V(τ)⋅W(τ)dτ
Where:
- Future value function $V(\tau)$ represents, in your current eyes, the value that this behavior brings at each future moment $\tau$ ;
- Weighted discount function $W(\tau)$ represents the degree of importance you attach to the value at each future moment $\tau$ (similar to the hyperbolic discounting function in economics that describes similar phenomena).
In other words, when we face choices, we don't simply add up all "future values" and then decide, but rather it depends on the weighted sum of values at all future moments. Generally speaking, values in the immediate future carry higher weight, while values in the distant future carry lower weight.
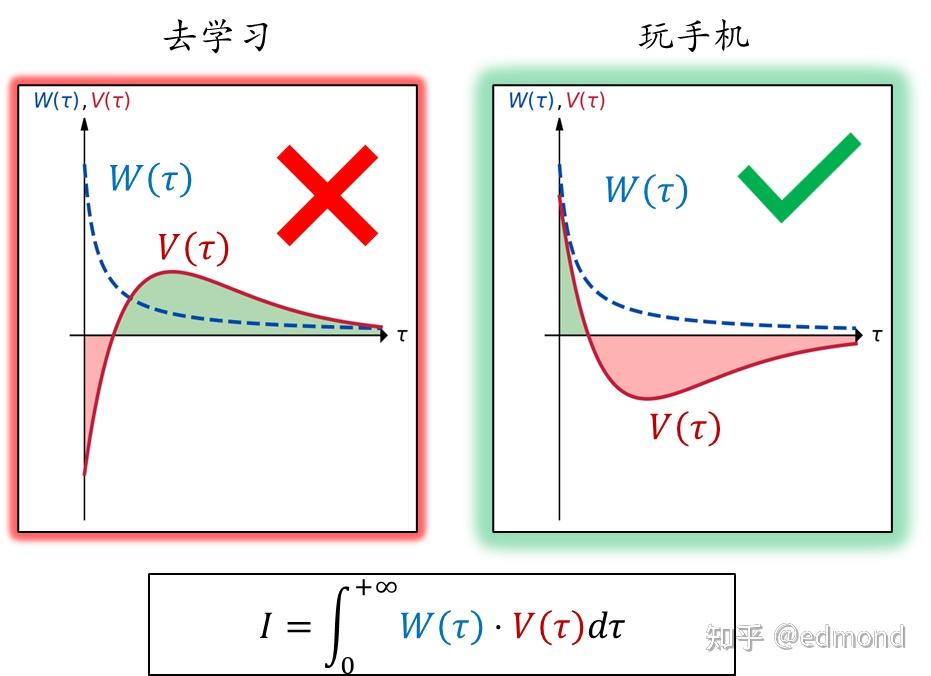
Take the example of "going to study vs. scrolling on phone" from earlier:
- If choosing to study, in the short term we face switching costs and the boredom of studying, so $V(\tau)$ is negative; but in the medium term, due to the pressure relief and satisfaction from studying, $V(\tau)$ turns positive; and in the more distant future, the impact of one study session will eventually dissipate, and $V(\tau)$ approaches 0 again;
- Scrolling on phone is the opposite: the short-term immediate pleasure makes $V(\tau)$ positive, but in the medium term it will produce anxiety and regret from ruining plans, turning $V(\tau)$ negative; and playing on the phone for one night ultimately won't change one's life, so $V(\tau)$ will slowly trend toward 0.
Ideally (that is, in a purely rational situation), if the weighting function $W(\tau)$ were a constant, then the net total value of studying would obviously be higher than playing on the phone.
However, our brains are often extremely short-sighted, with the weighting function $W(\tau)$ being very high in the short term and rapidly approaching zero in the long term.
Under this short-sighted weight distribution, the short-term advantage of scrolling on the phone, when multiplied by the weight, gains a huge advantage, and the integration result will actually be far higher than studying. This is why we ultimately choose to play on the phone.
(Note: In this article, we take a "assume without solving" approach to these two functions, only performing qualitative analysis, after all, quantitative analysis is not realistic for this problem)
3
In fact, you'll find that this seemingly simple mathematical model can explain almost all similar classic scenarios in life:
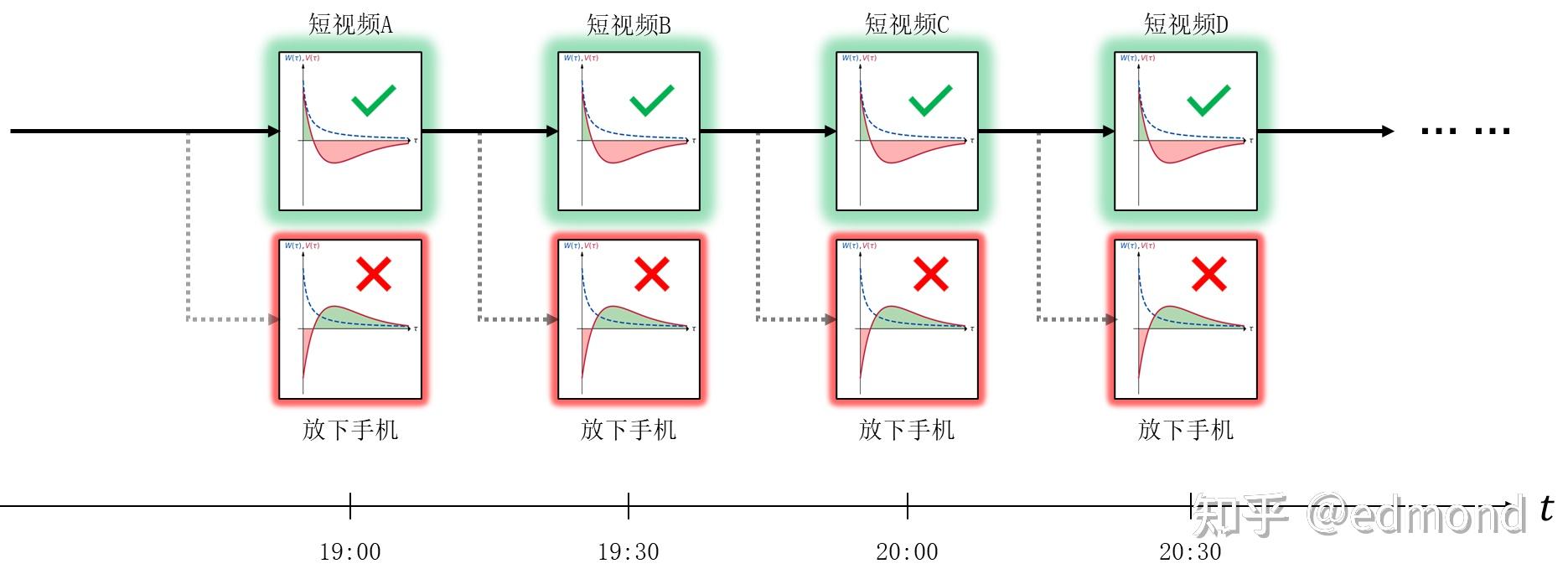
For example, still using the phone-playing example. You ultimately chose to pick up your phone, thinking you'd just play for a bit, then what happens?
From the moment you pick up the phone, the same story repeats infinitely:
- After finishing short video A, the short-term temptation of watching short video B is again higher than putting down the phone;
- After finishing short video B, the short-term temptation of watching short video C is again higher than putting down the phone...
From the perspective of you at every moment, $I(\text{short video}) > I(\text{put down phone})$ always holds true, so you will choose to watch the next short video at every moment.
So you scroll like this all night until 2 AM, 3 AM, when the cost of staying up late becomes increasingly considerable, gradually offsetting the temptation brought by short videos, and you finally go to bed filled with regret.
(Of course, some people, unable to face the anxiety and self-blame after staying up late, find the psychological cost of putting down the phone increasingly high, and end up simply staying up all night.)
But what if you chose to study at the beginning? You might be surprised to find that once you truly immerse yourself, continuing to study actually becomes easier and easier, and you may gradually feel less interested in scrolling on your phone.
This is due to the psychological phenomenon of "switching cost": When we switch from one task to another, this "switching" itself is naturally accompanied by a certain psychological resistance. This is also easy to understand in this model - to extract yourself from the current activity, you must first stop what you're doing, clear the working memory already loaded in your brain, and then forcibly switch to a new behavioral workflow.
This cost, mathematically, is equivalent to inserting a negative impulse function at the most sensitive $\tau=0$ position:
This is why it's harder to climb out after falling into indulgence, but it's also easier to persist once you start a task.
(To make subsequent representations more convenient, I won't draw this switching cost impulse function separately, but will automatically merge it into the value function $V(\tau)$.)
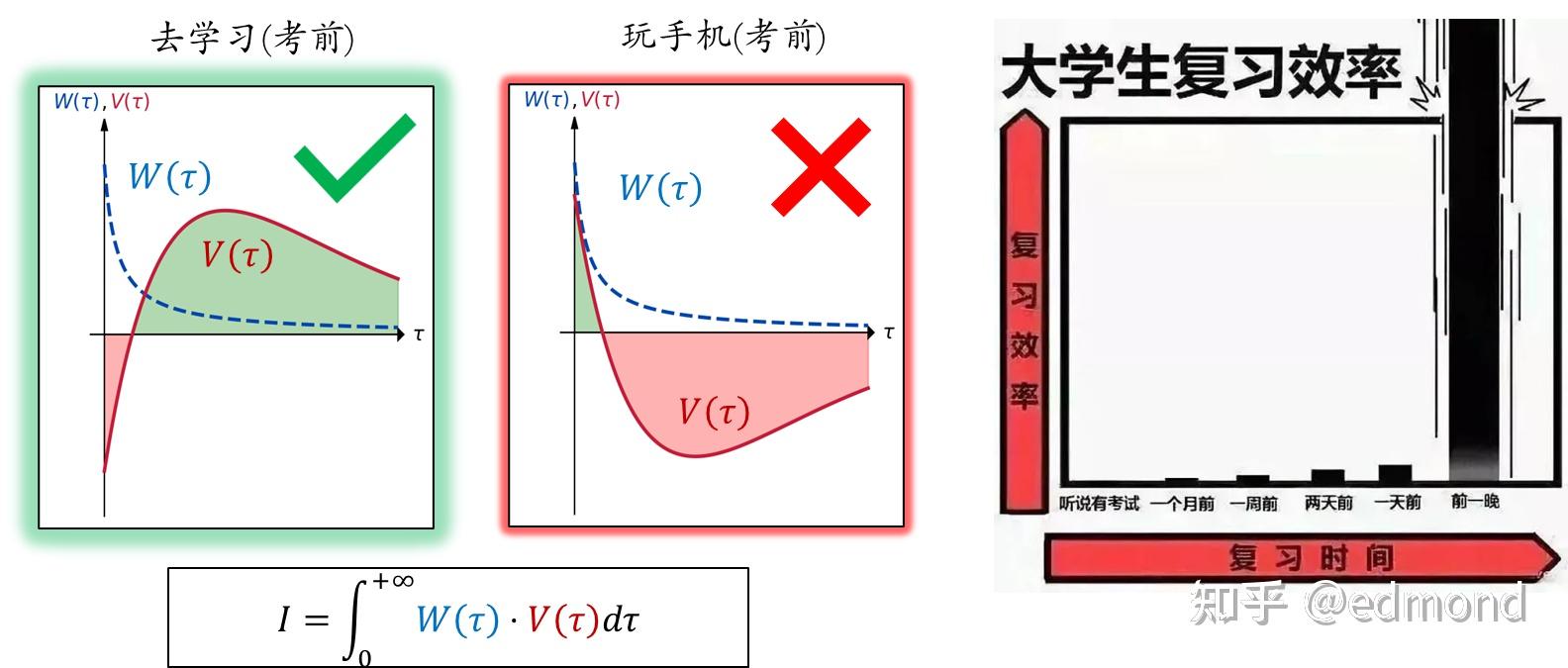
However, sometimes we can also naturally resist the temptation to play on our phones. The week before exams and the eve of deadlines are such times.
As mentioned earlier, the short-term pleasure brought by playing on the phone during normal times usually only causes some medium-term anxiety and won't truly have a major impact on our lives.
But exam week is different - if you're still addicted to short videos at this time, you'll fail the exam, producing a series of serious consequences, which might really change your life.
Thus, the long-term negative value of playing on the phone swells dramatically, brutally defeating the short-term temptation with extremely low weight! Therefore, the script for review week is usually a clear threshold: after a certain time point, your time investment suddenly increases sharply. The so-called "deadlines are the first productivity" actually follows this principle.
(Of course, for some people, the severity of these consequences also makes "going to review" increasingly heavy in meaning, increasing switching costs. The closer to the deadline, the less they can start, and they really do end up failing.)
Examples like this are numerous. It can be said that for individual behaviors, the success or failure of our self-control depends on one thing - whether the distribution of the value distribution function $V(\tau)$ over time is favorable.
4
Since $W(\tau)$ represents humanity's innate "short-sightedness," which is nearly fixed and very difficult for us to fundamentally change, we must ask a question: How is self-control even " possible"?
Here, we can make the second assertion of this article:
All effective self-control strategies for humanity are essentially constructing a transformation of the value distribution function $V(\tau)\rightarrow V'(\tau)$ , thereby making behavioral tendencies closer to the results of rational decision-making.
Let's give a few examples:
- Useless Method 1 (Long-term Rewards): Self-motivation, imagining "the beautiful life after future success," or doing "gamification," setting rewards for yourself after completing study. This is equivalent to adding a positive linear incentive in the distant future to the value function $V(\tau)$ of studying - but because the long-term weight is extremely low, this method actually doesn't work well and is usually useless;
- Useless Method 2 (Long-term Punishment): Setting punishments for playing on your phone, or going for a run or writing a self-criticism after playing on your phone. This is equivalent to inserting a negative value in the long-term future of the value function $V(\tau)$ of playing on phone - this method is equally useless;
- Slightly Useful Method 3 (Near-term Punishment): Locking up your phone or finding someone to supervise you. This is equivalent to increasing the switching cost of indulgent behavior in the near term, i.e., inserting negative values in the near term of its $V(\tau)$ - this method is useful, but not much;
- Useful Method 4 (Nonlinear Compression): For example, the "Pomodoro Technique" familiar to many. Its mechanism is actually to transform the $V(\tau)$ of "giving up midway" after starting to study, bundling and binding the sunk cost of the entire Pomodoro timer, then nonlinearly compressing it to the current moment - this is a relatively useful method, and we'll elaborate on it in detail when discussing CTDP (first-generation technique) later.
To more intuitively measure the effectiveness of these methods, we can also define a metric, which is the gain (G) of self-control strategies:
G=I′(study)I′(indulge)/I(study)I(indulge)G=\frac{I'(\text{study})}{I'(\text{indulge})}/\frac{I(\text{study})}{I(\text{indulge})}G=I′(indulge)I′(study)/I(indulge)I(study)
Simply put, it's the ratio of rational decision-making tendency before and after using the strategy. If we use this metric to test the vast majority of mainstream so-called "self-control methods" on the market, you'll find their gains are pitifully low. They either only work at the far end where weight is extremely low, or don't even act on the value function $V(\tau)$ at all:
For example, "Just do it," "Tell yourself you always have a choice," these types of marketing slogans and motivational clichés can actually get hundreds of thousands of likes on Zhihu and Douyin, showing how low the average cognitive level is regarding self-control topics.
And those who can achieve self-control through low-efficiency means (many of these people are indeed excellent) - it's not because these methods are so outstanding, but because they already have advantageous habits, environment, and personal conditions, only one step away from true self-control, so even weak stimulation can push them toward positive behavior.
The sad thing is, precisely because these advantages actually account for an extremely high proportion in personal achievement, people with these advantages rarely need to pursue truly efficient self-control strategies. The superficial methods they share after success have instead become the most widely spread mainstream cognition - this counterintuitive survivorship bias will be discussed more deeply at the end of the article.
5
Now, here comes the interesting part.
With this mathematical foundation, we can construct an extremely ingenious strategy that, through nonlinear compression and linear translation transformations of $V(\tau)$ at different time points, can almost conjure up astonishing positive gains for individual rational behaviors out of thin air.
More importantly, it can solve in one stroke the three most common ailments we face in self-control: giving up midway, the broken window effect, and difficulty starting.
And all of this is built on three core principles.
The first core principle is called the "Sacred Seat Principle."
Let's do such a thought experiment:
Suppose in a self-study room, there are many seats for you to choose from. One day, you have a whim and designate one seat as the "Sacred Seat," and establish such a game rule for it:
Sitting in any other seat has no special constraints, you can do whatever you want; but as long as your buttocks touch this "Sacred Seat," you must use your best state to focus and study for a full hour. Conversely, if you don't have confidence in achieving focus, then simply don't allow yourself to sit in this seat - rather choose other ordinary seats.
In short, this "Sacred Seat" must never be defiled by an unfocused buttocks.
Of course, merely imagining such a rule doesn't inherently possess any real binding force. But what if you really seriously executed it once?
One day, you really sat down, and as soon as your buttocks touched that seat, you really used your most serious state to study for an hour.
A magical thing happened: From the moment you first successfully executed this rule, this seat that was originally just imagined truly became valued in your heart! From then on, your possibility of sitting in this seat and casually playing on your phone would truly be much lower than before:
At this time, you add a new game rule:
Record the first focused session as #1. Henceforth, every time you successfully focus for an hour, it can serve as proof of work, adding a numbered record to this "Sacred Seat": #1, #2, ...#N. But as long as there's one failure - for example, if you scrolled on your phone while sitting there, or only sat for ten minutes before leaving - then all records will be cleared to zero, and next time you can only start over from #1.
As this chain continues to extend and proof of work continues to accumulate, the value of this virtual seat will strengthen time after time. When the node count of this task chain grows to #10, #20, #30, the binding force of this rule simply becomes tangible - you may even become cautious, not even daring to breathe heavily, lest there be even the slightest disrespect to the rule.
Note: "Sacred Seat" is just one example. In fact, it can be any symbolic object - a clipboard, a hat, a message to a WeChat account can all be a Sacred Seat. But it's best to be something visible and tangible. For example, the Sacred Seat I currently use is a blue hat - as long as I wear it, I must focus for an hour.
(The clever reader has surely thought of the problem of this rule collapsing + you being unwilling to sit down. Don't worry, this is precisely what sections 8 and 9 will solve.)
(To avoid many people's misunderstanding, I need to state here that this is not the final version of the method. What truly works is the mathematical mechanism, and it has nothing to do with so-called "morality," "ritual sense," "psychological suggestion," or "now or never." This will be explained in detail later.)
6
This magical binding force actually comes from humanity's innate obsession with "maintaining records."
Many fitness or learning apps have a "consecutive check-in" feature. Many people, no matter how tired or exhausted, will force themselves to memorize vocabulary for 5 minutes just to maintain that "365-day consecutive check-in" record on Duolingo. Someone who has quit smoking or drinking for 10 consecutive days will find it harder to give up seeing that number 10 than on the first day.
— Just an imagined record is enough to produce absurdly strong binding force.
Looking closely, this binding force actually comes from two points:
- On one hand, the longer the record is maintained, the more real time and energy you've invested to maintain this record. Behind each successful task node in the chain is real "proof of work" and sunk cost;
- On the other hand, this record is often accompanied by a subtle "future value expectation": You think this record has value → You're afraid of losing this record → It generates binding force → This binding force helps with your future self-control, and your future self-control relies on it → This record becomes more valuable. The higher the value, the stronger the binding force; the stronger the binding force, the higher the future expectation; the higher the future expectation, the higher the value...
However, all "records" naturally have the characteristic of "all or nothing": Once you break this record, all the sunk costs and future expectations accumulated through this hard work will immediately and suddenly be completely lost at the moment $\tau=0$ :
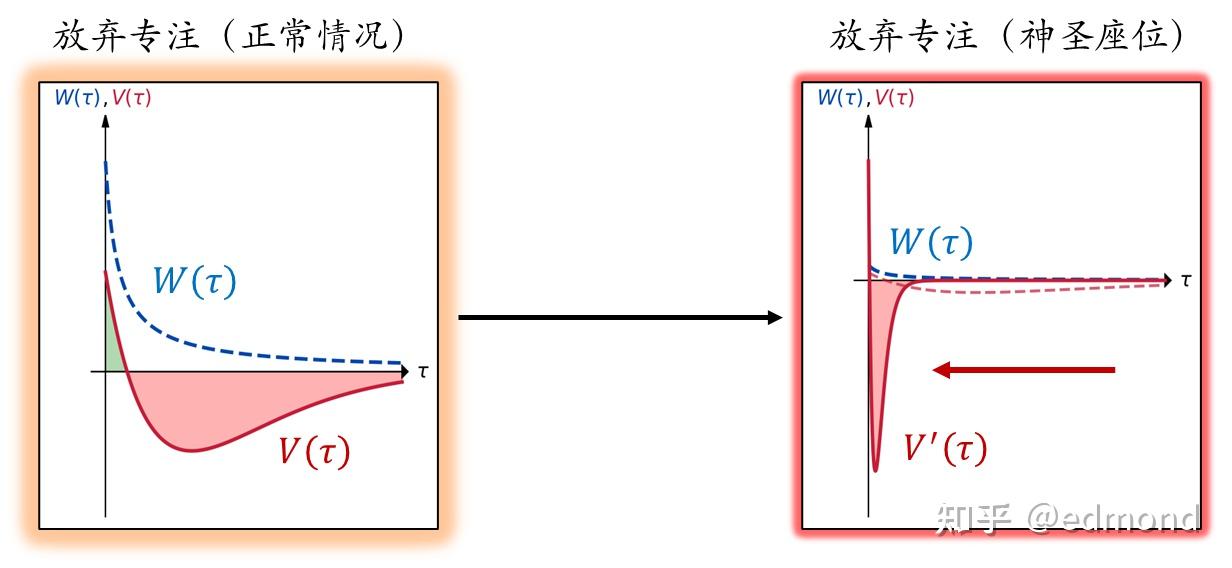
This is the mathematical essence behind the "Sacred Seat Principle": Nonlinear compression transformation of $V(\tau)$ .
When you sit in this seat, all the value invested in all nodes of the entire task chain in the past, and the expected value of the future, will be dramatically compressed in the value function of the "giving up focus" option, condensed into a peak extremely close to the origin ( $\tau=0$ ) - any short-term temptation to break the rule must actually immediately face the challenge of the entire chain's accumulated and future value.
And the most wonderful thing is that this holds true at every moment of the focus task. When the sunk cost accumulates to a certain degree, there will no longer be any short-term temptation that can challenge such an astonishing barrier.
7
This "all or nothing" value binding principle is also why many classic self-control strategies truly work:
For example, the Pomodoro Technique - each Pomodoro timer is actually equivalent to a "small Sacred Seat": It bundles the sunk cost and future expectation of the entire focus period into one whole "tomato." Once you slack off or give up during the Pomodoro period, you immediately bear the huge cost of losing the entire "tomato" at the current instant.
This way, your choice at every moment is no longer a comparison between "immediate temptation and current task," but becomes a competition between "immediate temptation and the total compressed tomato value" - this is the real core mechanism behind why the Pomodoro Technique truly works.
There are many more such examples. Many people have also had such experiences:
One day you learned a brand new self-control method, felt it made a lot of sense, and enthusiastically invested in practice. At the beginning, even if that method is actually useless, you'll find it works like magic.
But strangely, after a few days, the initial novelty gradually fades, you begin to violate the rules frequently, the effectiveness of the method rapidly declines, and ultimately completely fails and is abandoned by you.
This is a kind of illusion similar to a "beginner's grace period": Any self-control method appears to be useful in the first few days, but what truly works may not be the method itself, but rather your "future expectation" of this method.
When you entrust your future self-control hopes to this method, this "entrustment" briefly truly grants it binding force. However, if the method itself is ineffective, this temporary binding force ultimately cannot support it to survive long-term in the complex real environment. Once any single violation or wear occurs, the entire method's credibility and value will quickly collapse with the broken window effect.
The most beautiful aspect of the "Sacred Seat" design is that it is naturally a distributed, decentralized design in terms of time. It is only responsible for those selected, purified states of sitting in that seat, without needing to be exposed to all time or be responsible for long-term states, thereby maximally avoiding wear.
In other words, you can go to parties, drink, play games, waste several days or even a week after completing task #1 in full state, but when you next walk back into the self-study room to start #2, the Sacred Seat is still that Sacred Seat, and its binding force won't weaken in the slightest.
8
Of course, even within this selected state, the "Sacred Seat Principle" is not completely without loopholes.
As mentioned earlier, once you sit in this position, you must study in "the best state" for an hour. So the question arises: how do we define this "best state"?
- If I go to the bathroom midway, does it still count as "the best state"?
- If I answer a phone call or pick up a delivery, does it still count as "the best state"?
- If someone messages me and I reply, does it still count as "the best state"?
- If all of these count, then scrolling on my phone midway and watching a couple of short videos should also count as "the best state," right?
You'll find that the "ideal state" simply doesn't exist. Once any self-control strategy enters actual combat, it must face complex and variable real situations. On the surface, a self-control strategy is just a simple constraint; but in actual application, all self-control strategies are equivalent to numerous implicit, tiny "sub-constraints," and each sub-constraint can be tested and challenged:
- If you allow yourself flexible discretion, the method's binding force will be worn away bit by bit in one "this time is special, not to be taken as precedent" rationalization after another, producing the broken window effect, ultimately being eroded full of holes;
- But if you don't allow any exceptions at all, this method becomes rigid and brittle. When you encounter a situation where you absolutely must make an exception, the rule may instantly and completely collapse.
This "gradual broken window effect" is precisely the fundamental reason why the vast majority of methods similar to "gamification" or "establishing rules" eventually fail. What matters is not what game the athletes play, but the logic of separating athletes from referees.
To solve this problem, let's introduce a more ingenious second core principle: the "Precedent-Setting Principle."
(Note: it's "Precedent-Setting" (bì), not "not to be taken as precedent" (bù))
Since you yourself also know clearly that once there's a first "not to be taken as precedent," there will inevitably be countless subsequent violations, then why not do the opposite and forcibly require yourself to "set a precedent" - that is, conversely requiring yourself to violate in the future!
Specifically, when you face any judgment that seems like a violation, like the "case law" in Western legal systems, you can only choose one of the following two options:
- Immediately judge that the "Sacred Seat" rule is completely broken, the chain is severed, thoroughly clear all task records, admit the binding force has completely returned to zero; next time honestly start over from #1;
- Judge that the current behavior is allowed, but as long as it's allowed this once, the same situation must be allowed in the future; for the entire subsequent lifecycle of this task chain, it will thoroughly lose binding force over this behavior.
Your "best state" is not defined by any subjective or objective standard, but is dynamically formed by countless "precedents":
- Going to the bathroom midway, does it still count as "the best state"? It can count, but as long as it counts this time, it must always count in the future;
- Replying to messages midway, does it still count as "the best state"? It can count, but as long as it counts this time, it must always count in the future;
- Scrolling on your phone for two minutes midway, does it still count as "the best state"? It can count, but as long as it counts this time, it must always count in the future;
This way, what you're weighing is no longer a single isolated choice, but whether to permanently give up the rule's binding force over this behavior at this current instant. The cost presented to you is the real long-term cost of allowing this behavior.
Now in your eyes:
- For behaviors that rationally shouldn't be allowed (such as playing on your phone), you sitting in the seat are very clear: as long as you allow this "exception" today, then every time you sit in this seat in the future, you'll cite this behavior as a "precedent" to violate (moreover, the rule requires you to violate), and you can never redefine this behavior as a violation;
- But for situations that rationally should be allowed (such as going to the bathroom), your future self can also feel at ease giving yourself permission, without any concerns about the rule's credibility.
Ultimately, the decisions you make truly become the most aligned with long-term rationality. Because you thinking of the present (as the athlete) and you thinking of the future (as the referee) have already reached consensus under this mechanism in a wonderful way - just like this, you yourself have reached a Nash equilibrium across time with yourself.
When this method runs long-term, the rule's binding boundaries won't gradually erode and collapse like traditional methods, but rather slowly and $\epsilon-n$ style, with a precision of "always just enough," gradually converge to the boundary closest to rational decision-making: both able to tolerate truly necessary exceptions and effectively prevent unnecessary self-indulgence.
This is the ingenious aspect of the "Precedent-Setting Principle."
9
Alright, now we have a perfect "Sacred Seat." But a new problem arises:
The more sacred the seat, the less you dare to sit in it.
Indeed, the state of sitting in this "Sacred Seat" is very perfect. However, this seat is too sacred, too perfect, so much so that the commitment of the action "sitting in the seat" is too heavy, and you'll become increasingly unwilling to sit down - that is, the commonly mentioned "difficulty starting" problem.
This is precisely why people always like to say "perfectionism leads to procrastination" (although strictly speaking, the essence of procrastination isn't perfectionism, but rather the rise in switching costs caused by overly high expectations).
At this point, it's time for our third core principle: the "Linear Time-Delay Principle."
And this principle, from a mathematical perspective, can elegantly solve in one stroke the "procrastination" problem that has plagued countless people for so long.
Let's do another simple thought experiment:
- Suppose you find a typical procrastinator and ask them: "Are you willing to start studying right now?" They'll mostly shake their head and refuse;
- But if you change the way you ask: "Then are you willing to start studying tomorrow afternoon?" You don't even need to wait that long: "How about starting in 15 minutes?" This time, they'll surprisingly mostly agree! And the longer this delay, the higher the probability this person will agree.
Why does this strange phenomenon occur?
Let's return to the mathematical model from earlier to explain:
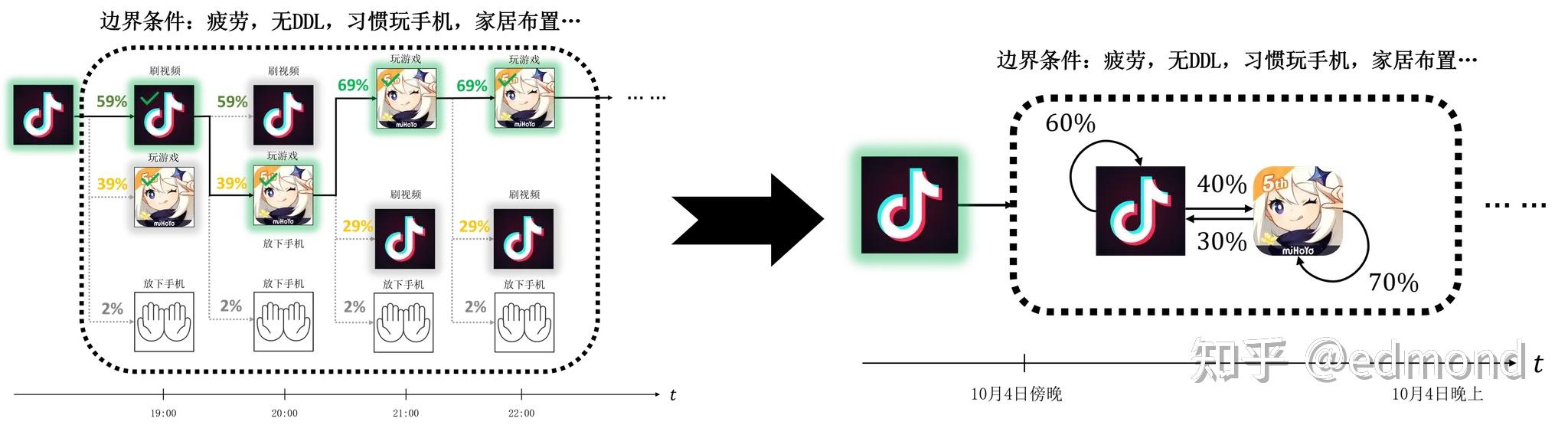
- When you consider "whether to start studying right now," just as analyzed earlier, the negative value of the value function $V(\tau)$ happens to be at the high-weight near term of the weighting function $W(\tau)$, so you'll feel strong resistance;
- However, when you consider "whether you're willing to start studying in 15 minutes," the situation is completely different: This actually amounts to shifting $V(\tau)$ backward on the time axis by 15 minutes, arriving at $W(\tau)$ 's relatively flat region! Compared to the option of indulgence, this almost smooths out its huge disadvantage in the short term.
This also explains a very common phenomenon in daily life: we always harbor blindly optimistic fantasies about our future self-control.
In the hyperbolic discounting function, weight decreases over time first steeply, then gradually - the weight 10 minutes from now and the weight 1 hour from now might differ vastly, but the weight 1 day plus 10 minutes from now and the weight 1 day plus 1 hour from now differ almost negligibly.
When we consider future choices in advance, it's equivalent to integrating using $V(\tau-\Delta\tau)$ after shifting, then with $W(\tau)$. The longer the shift distance, the flatter the $W(\tau)$ actually participating in integration, and naturally the closer to the rational state. This is why we're often blindly optimistic when making summer vacation plans, naively thinking we can really put down our phones after just five minutes of scrolling.
And here comes the climax of this method:
We can establish a parallel "auxiliary chain" in addition to the main task chain, also protected by the Sacred Seat Principle, also "setting precedent" for all situations, and its contained binding rule is very simple:
- Set a simple action as a reservation signal, such as snapping your fingers once;
- Once this signal is triggered, you must - within the next 15 minutes - sit! down! in! that! Sacred! Seat!
As the saying goes, better to dredge than to block. The best way to overcome procrastination is to first admit and respect procrastination.
Since the threshold for "reserving to start in 15 minutes" is far lower than the threshold for "starting immediately," your present self can start the reservation without any pressure.
15 minutes later, that auxiliary chain's past and future value will gradually compress at $\tau=0$, condensing into a sharp, sky-piercing needle - forcibly puncturing that door of "switching cost" and "starting difficulty."
(By the way, a fun fact: When I first came up with this method, one night I couldn't sleep and accidentally snapped my fingers, so I had no choice but to reluctantly climb up at 3 AM to study for an hour.)
Now, combining the three core principles above, we finally have the complete first-generation self-control technique:
Chained Time-Delay Protocol (CTDP)
10
Here is the complete description of the Chained Time-Delay Protocol (CTDP):
CTDP is a behavioral constraint strategy constructed based on three core principles (Sacred Seat Principle, Precedent-Setting Principle, Linear Time-Delay Principle). Specifically, it requires you to build two parallel task chains (main chain and auxiliary chain), and strictly follow these steps:
Main Chain (Task Chain):
- First, designate a specific object as a marker, as the "Sacred Seat" (In fact, the Sacred Seat is just a metaphor; it can be anything - a specific chair, a special pen, a hat, or even a message sent to your specific WeChat account)
- Once you trigger this marker, you must complete a clear focus task in "the best state";
- Each time you successfully complete a focus task, you can record a node in the main chain: the first success is #1, the second success is #2, the third is #3, and so on;
- If at any point midway through a task you seem to have done something inconsistent with "the best state," you must choose one of the following two options ("Precedent-Setting" principle):
- Judge that the entire main task chain immediately fails, clear all currently accumulated node records, and next time you can only start over from #1;
- Judge that the current behavior is allowed, but from now on, this behavior must also be permanently allowed in subsequent tasks and can no longer be considered a violation;
Auxiliary Chain (Reservation Chain):
- Define a simple reservation signal, such as snapping your fingers, starting an alarm, indicating that the main task will start in 15 minutes;
- Once you trigger this reservation signal, within the next 15 minutes, you must go trigger the marker corresponding to that Sacred Seat and start a main chain task;
- If after triggering the reservation, you don't trigger that marker within 15 minutes, then the "Precedent-Setting" principle also applies:
- Either thoroughly clear the reservation chain's records and admit the reservation chain has failed;
- Or allow the current situation, but from now on, the reservation chain will thoroughly lose all binding force over this situation;
Thus, by simultaneously using nonlinear value compression (Sacred Seat) + case law constraint (Precedent-Setting) + linear time translation (reservation mechanism) through three ingenious mechanisms, we hack away the influence of starting difficulty, broken window effect, and short-sighted decision-making.
Through just a few thought experiments, we've constructed a self-control strategy that can nearly conjure up huge gains for rational behavior out of thin air, without external supervision or even insufficient willpower. Moreover, its binding force comes entirely from proof of work at each node, only responsible for these distributed, selected nodes, and won't be eroded by exposure to long-term state fluctuations.
By relying on the CTDP strategy, for any important task, we can achieve both easy starting and easy persistence, without losing effectiveness in the long term - this seemingly impossible triangle, we want it all.
11
Of course, the CTDP described earlier is more of an idealized version. In real life, its application is far more flexible and interesting than what was just described.
For example, does the "Sacred Seat" really have to be a seat?
Actually not necessarily. It can be any specific, easily distinguishable marker. For example, the marker I usually use is a dedicated WeChat account. Every time I start a task, I send a message to trigger the task while also recording nodes and declaring goals;
Secondly, the task chain itself doesn't necessarily have to be strict linear progression (#1, #2, #3...). You can completely construct a top-down hierarchical organization:
- For example, three unit-level nodes can form a 3-hour task group, recorded as ##1;
- Three task groups form a day-level task cluster, recorded as ###1;
- Three task clusters form a three-day-level task formation, recorded as ####1;
- Two to three formations can be managed with a week-level task ensemble, recorded as #####1;
And each unit can have its own requirements. For example, a ## task group can require that after completing the first two # units, a reservation signal must be executed once, which can string together three # units. This way, we're like a military command system, organizing huge task chains in a top-down "rule of three" manner:
Similarly, the content of task units doesn't necessarily have to be monotonous focused studying. To use a metaphor, it can also be divided into different "troop types."
For example, studying, doing experiments, reading papers = "assault units"; information gathering = "reconnaissance units"; making plans = "command units"; handling miscellaneous matters = "special service units"; exercise and training = "engineering units"; preparing and cooking meals = "cooking units"...
And a large task cluster or task formation can be like a modern combined arms team, composed of multiple troop types -
A main battle task cluster focused on work can be synthesized from 7 assault units + 2 reconnaissance units;
A weekend rest logistics task cluster can be 1 command unit + 3 special service units + 2 engineering units + 1 cooking unit synthesis;
During vacation, a three-day formation that balances exercise and self-study can be synthesized according to 6 assault groups + 3 engineering groups.
You'll find that this task chain structure naturally accomplishes what people often call "goal decomposition." Meanwhile, "gamification" doesn't need to be deliberately designed - because when you truly face a large task, the style is like this:

Diary, take note, I make the following deployment adjustments:
With the fourth task cluster, plus the eleventh task cluster and fifteenth and sixteenth two independent reconnaissance groups, strengthen next week's assignment deadline defense line;
Second, third, seventh, eighth, ninth five task clusters, plus the sixth task cluster's seventeenth assault group, concentrate forces to complete notes;
Tenth assault group plus one assault group, on the TOEFL and GRE frontline, blocking vocabulary arriving at review time;
Twelfth task cluster cooperates with twelve independent units to besiege previously found knowledge gaps;
Fifth task cluster and sixth task cluster's two reconnaissance groups search for materials;
Fourteenth task cluster as total reserve, don't move;
Some additional notes:
In practice, using only a simple reservation signal is still too fragile because sometimes when the 15min is up, I might be in the bathroom/outdoors, and starting a task isn't realistic. So I'll design two startup signals as a buffer:
- Reservation startup signal: The signal is snapping fingers once. Once triggered, the "immediate startup signal" must be executed within 14min30s (leaving a buffer to prevent really using up 15min);
- Immediate startup signal: The signal is snapping fingers three times. Once triggered, you must start the task as soon as possible according to available conditions.
Additionally, this strategy of "Sacred Seat + Precedent-Setting + Linear Time-Delay" combined can also be easily extended to any aspect of life:
- For example, to initiate running exercise, you can use a specific gesture as a reservation signal - doing n repetitions of the movement means you must run for 5×n minutes;
- To address the common shower and going-out procrastination problems for ADHD populations, you can also specifically set corresponding shower reservation signals and going-out reservation signals;
Extending it further, you can almost "remotely control" your daily life directly with simple gestures or movements - in an extremely easy and elegant way, thoroughly eliminating procrastination problems.
12
Up to this point, the content of the first-generation self-control technique has been completely presented.
Looking back, this technique, whether from principle design, practical implementation, or the ingenuity of the method, has far surpassed those superficial motivational slogans, to-do checklists, or gamification designs on the market.
Indeed, in the several years after CTDP's birth, it produced astonishing effects on me personally.
I must honestly say that my own self-control foundation is really quite terrible: from elementary school to high school, I was deeply addicted to games day and night, plagued by ADHD for years, with study habits and life order in complete chaos. From childhood to adulthood, I couldn't listen to even one class, and ultimately tested into a 985 university. In early university, after the environment relaxed, I could even be distracted during exam week, unable to review even half-heartedly. The example mentioned earlier about getting closer to DDL but becoming even less able to study was once my real self - truly at the bottom in terms of self-control foundation.
But since CTDP's birth, I achieved for the first time in my life sustained self-discipline lasting weeks or even months. With this technique, I could extremely easily start tasks and maintain high focus throughout the entire day without burden. ADHD problems seemed to be alleviated overnight. Not only did my late university grades improve significantly, I even achieved study abroad exchange, published papers, successfully conquered TOEFL and GRE, and ultimately completed a hardcore master's program.
Especially during peak state periods (such as while preparing for TOEFL and GRE), it could even let me efficiently mobilize 8-10 hours daily for two consecutive months. Fighting with large armies of dozens of task ensembles and hundreds of task units, all could move at command, advance and retreat in order, seamless as flowing clouds and water.
There was even once when I caught a cold for three days midway through exam review, and I could still calmly calculate its impact on the exam fifteen days later, and calmly deploy eight or nine ### task groups from the total reserve deployed seven days later to fill the gap.
(For example, this is a plan from over a month before a certain exam, where each unit cell represents one ### level task group)
Faced with such unprecedented efficient self-discipline, I was once optimistically under the impression that the mansion of self-control had already been built, and what remained was just minor repairs and patches.
However, I soon discovered that CTDP wasn't useful at all times. Specifically, I observed a clear bipolarization phenomenon:
- When the overall state was already favorable for self-control, especially when there were clear pressures and goals like DDL, such as during pre-exam review periods or times with many urgent tasks, CTDP could indeed maximize the use of these pressures, making self-control and discipline reach unprecedented heights, with almost every hour flowing like water, at my command;
- However, when the overall state was originally unfavorable for self-control, such as during idle time at home, physical and mental fatigue, or without clear task goals, I often extremely lacked even the willingness to trigger the reservation startup signal. Even after forcibly starting multiple times, it would collapse after just a few # tasks.
Therefore, in the following three or four years, I tried countless times to improve and upgrade it. However, CTDP seemed to have exhausted the limits of self-control strategies from the microscopic perspective of "individual behaviors at the 1-hour scale." No matter how I modified it, over the years it could never advance even an inch, and self-control state always showed strong stage-dependency and environmental dependency.
Just like this, this bottleneck troubled me for several years. Until five years later, I finally found a deeper perspective to explain all of this
— Not focusing on the traditional "motivation," "rewards and punishments," or "constraints," but using the perspective of "scale" to view the entire system!
13
Under this new perspective, the various behaviors in our lives are not composed of simple, isolated, single decision nodes painted solely by the immediate $V(\tau)$ . In reality, it's more like a "behavioral tree" composed of countless continuous, interwoven decision nodes.
In this behavioral tree, the direction of each node highly depends on the choices of the nodes before it; and its macroscopic direction at various time scales is highly determined by various large and small scale factors in life. And among them, the vast majority of nodes are simply not suitable for our limited free will, or self-control strategies driven by free will, to intervene.
Let's recall the phone trap example from the beginning:
One evening after dinner, you lie on the sofa with the mentality of "just scrolling for a bit," casually opening a short video app:
Just as analyzed earlier, after finishing each video, you face the microscopic choice of "watching the next video" versus "putting down the phone" again. But unfortunately, the relationship $I(\text{short video}) \gg I(\text{put down phone})$ holds true for every microscopic node, so you can't put down the phone at any node.
Suppose based on all your past choice records, we statistically calculate the probability of you ultimately taking either of the two branches, you'll find the difference between the two is extremely disparate - perhaps as high as 99% versus 1% (this is just a conceptual example, actual statistics aren't needed).
Now, we can introduce a key assumption - the "Limited Free Will" assumption:
Free will exists, but it is also limited. The smaller the tendency difference between options, the higher the probability that free will can effectively intervene. If it's a 60%:40% difference, free will can still intervene; but when the difference between options is too large, such as reaching 99%:1%, free will becomes almost powerless.
In fact, the moment you lie on the sofa and open a short video app, your behavioral state is like a fighter jet locked by missile radar, trapped in an "inescapable zone" that's difficult to escape from. Within this zone, you cannot break free from inside merely through the tiny struggles of free will, and can only sit and wait for destruction in a statistical sense.
Until the anxiety of staying up late slowly grows, the numbness from scrolling slowly develops, and the tendency difference between the two options slowly narrows to a range where free will can intervene, only then can you successfully change out of this state.
In other words, when you chose to pick up your phone and lie down on the sofa at that moment, you had actually already determined the next several hours of wasting away in a larger-scale sense.
Based on the above observations, we can also propose a further definition:
When a string of decision nodes has a probability difference exceeding a certain threshold (such as 90%:10%), we can consider it beyond the intervention range of free will. Then, directly ignore the option with lower probability and coarse-grain these microscopic nodes into an overall "inescapable zone."
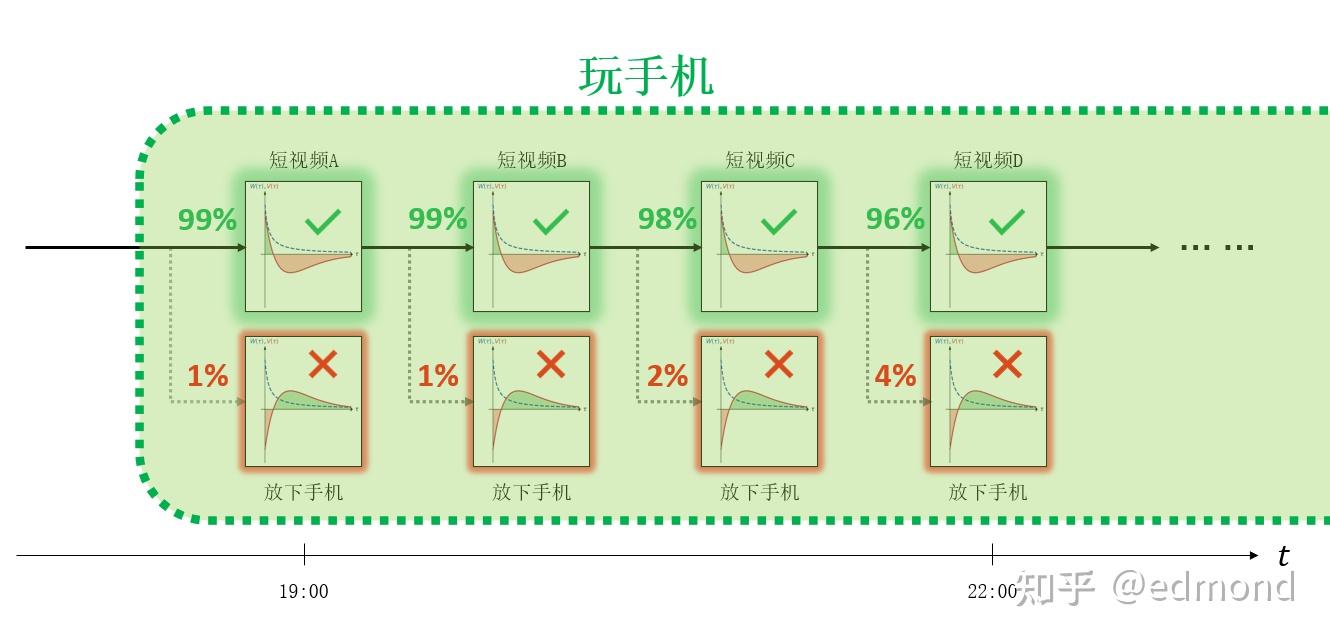
If we look from a larger scale, within these "inescapable zones," those seemingly independent decision nodes have already been determined in a statistical sense by larger-scale factors (such as immediate temptation, current emotions, physical fatigue, and deeply rooted habits). Small-scale free will choices, such as whether to scroll through videos or play games, which specific short video to watch, become unimportant instead.
RSIP Recursive Stabilization Iteration Protocol
14
This phenomenon where the importance of various influencing factors waxes and wanes at different scales is not limited to the self-control domain, but widely exists in various complex systems.
In statistical physics, there is an elegant and profound theory called Renormalization Group Theory, which describes precisely this phenomenon. In 1966, American physicist Leo Kadanoff proposed such an idea:
When you change the scale of observation, the internal degrees of freedom of the system will continuously merge (coarse-grain), the system's macroscopic behavior will gradually be dominated by a few key variables, while a large number of microscopic variables gradually become unimportant.
To simply understand this method, imagine such a small game:
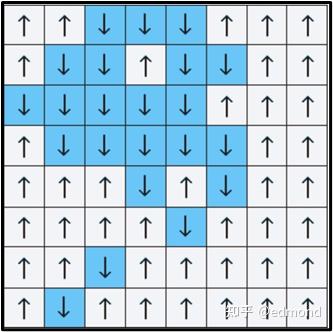
Before you is a very large lattice chessboard, with an arrow on each square, pointing either up (↑) or down (↓). We can design some rules to influence the arrows' directions, for example:
- We can add a rule to make each arrow tend to be consistent with its neighbors;
- Or conversely, make arrows tend to oppose their neighbors;
- We can also add local noise and disturbances;
- And furthermore, sometimes we can apply overall external intervention;
Under these densely interwoven local rules, many tiny disturbances, even a tiny change in one square, might spread to the surroundings, forming complex chain reactions. You might think that to analyze the overall pattern, you'd need to count every single arrow clearly.
But Kadanoff said: No need for such complexity. As long as we're willing to be a bit "blurry," to see a bit more coarsely, patterns will automatically emerge.
He designed an ingenious "coarse-graining" game rule:
- Merge adjacent 2×2 small squares into one large square;
- Use a "winner takes all" approach to decide this large square's direction (for example, three ↑ and one ↓, then the whole block is marked as ↑. If the numbers are equal, randomly choose a direction, or handle according to some simple rule);
- Then, continue repeating this merging operation with the newly obtained large squares...
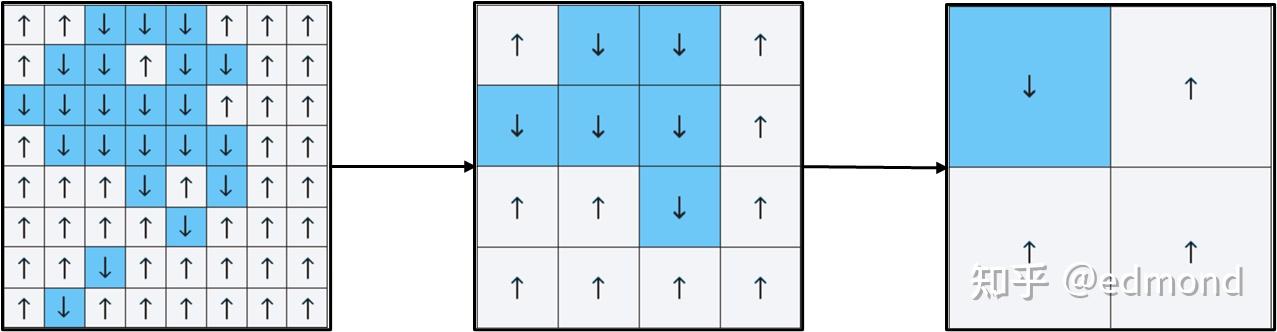
After round after round of "merging" coarse-graining, our perspective pulls farther and farther back, becoming increasingly blurry. The arrow diagram that initially looked chaotically detailed in its details ends up with just a few large regions, perhaps with most directions tending toward consistency.
What happened in this process?
- First, those local rules with small scope of action, each doing their own thing, will be submerged during merging, or cancel each other out on average, ultimately completely disappearing at large scales. The structures thus produced therefore gradually fade away;
- Conversely, those trends with wider scope and stronger consistency can survive in each layer of coarse-graining, gradually becoming prominent at larger scales;
- Thus, this coarse-graining not only changes the lattice, it can also change the strength of the "rules" themselves! Whether a rule is important depends on which scale you observe it at. Factors that are crucial at the microscopic scale may have no trace at large scales; while those seemingly weak but consistent trends may instead become the system's ultimate dominant force.
Let's consider a simple example.
Suppose on this chessboard, there are two types of forces competing with each other:
- One is short-range exchange interaction, very strong, but only affects nearest neighbor squares, making adjacent arrows tend toward consistency;
- The other is long-range dipolar interaction, relatively weak, but can act over longer distances, attempting to make arrows in regions point in opposite directions.
(Note: In the real world there might also be complex factors like anisotropy, thermal fluctuations, defects, stress, etc. This is just a very simplified hypothetical discussion)
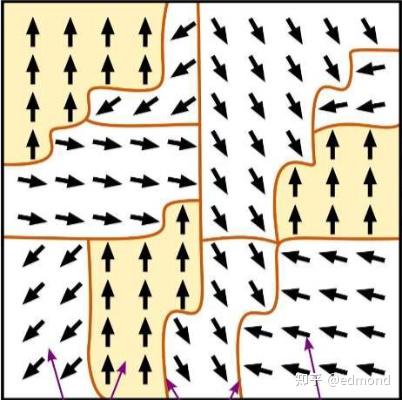
Without external intervention, these two forces begin a tug-of-war:
- Exchange interaction tends to pull all local squares into one direction, forming numerous locally homogeneous small regions;
- Dipolar interaction won't allow the entire system to point in the same direction for too long; it tries to "pull" these regions from afar, promoting alternating directions between them, forming mutually canceling arrangements;
Ultimately, under the competition and compromise of these two forces, a delicate balance is reached: You'll see large patches of arrows automatically cluster, forming "islands" of varying sizes and alternating directions. Each island is internally uniform in direction, while different islands differ from each other. These islands nestle against each other, ultimately stabilizing into a complex yet stable "puzzle" structure.
In the real world, this phenomenon is called magnetic domains, which is precisely the result of the classic short-range exchange - long-range dipolar competition model.
15
So, when we observe this chessboard at different scales, what happens?
- At the microscopic scale, we mainly see patches of highly uniform local regions: At this point, exchange interaction is very powerful, rapidly making surrounding squares' directions tend toward consistency; while dipolar action, being too weak, is almost imperceptible at this microscopic perspective.
- But when we coarse-grain to larger scales, what we see are large blocks of different directions alternating with each other: At this point, although exchange interaction is strong, its range of action is too short, only able to influence internal small-scale unifying trends. Its voice doesn't grow with coarse-graining; conversely, dipolar interaction has sufficient range - at large scales, its weak action continuously adds up, slowly accumulating, gradually occupying a dominant position, forming obvious macroscopic structure.
This is the most profound point revealed by renormalization group thinking.
The importance of a factor often depends on the observation scale you're at - rules that are crucial at small scales may be completely averaged out at larger scales; while those long-range trends that are almost imperceptible at small scales may accumulate layer by layer during coarse-graining, ultimately dominating the system's macroscopic direction.
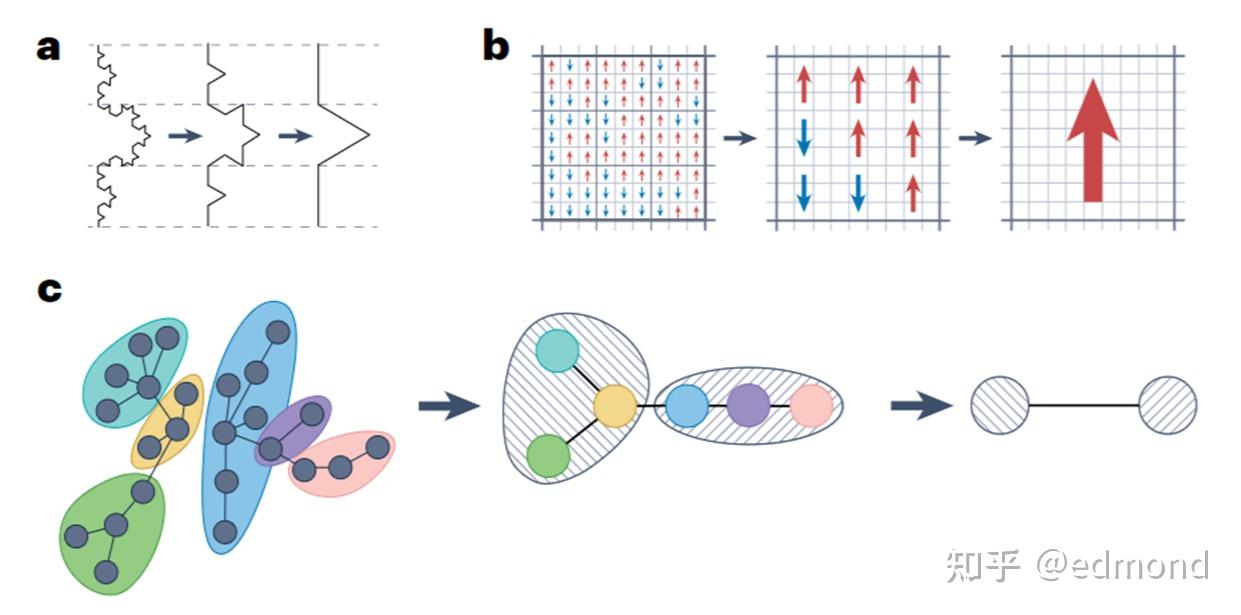
This is one of the most universal laws of the entire physical world:
- A glass of water is countless molecules in complex and chaotic collisions microscopically, but macroscopically can be completely described with just a few simple variables: temperature, pressure, and volume;
- A magnet at the atomic scale has chaotically disordered magnetic moments, but at the macroscopic scale condenses clear north and south poles;
- Every atom of a spring follows complex quantum mechanics, but from the outside, macroscopically it's just a simple Hooke's law $F = kx$;
- In financial markets, small-period trends no matter how complexly they fluctuate will ultimately follow the script set by large-period trends.
As the observation scale continuously enlarges, most local fluctuations, short-range volatility, and microscopic rules will automatically be merged, be offset, be absorbed into other variables. And the system's ultimate macroscopic behavior only depends on very few variables with wide range, strong consistency, that can continuously accumulate and survive at larger scales.
(Note: These two sections are only metaphorical analogies to life, not rigorous reasoning)
16
What's shocking is that such renormalization thinking can actually be extended to life itself.
Now, let's also establish a rule for our life timeline like the "winner takes all" rule for merging small squares: When the probability difference between various behavioral options exceeds a certain threshold (such as 90%:10%) within a period of time, we consider free will unable to intervene, then merge this time period, coarse-graining it into an "inescapable zone."
— You'll find that most of our life is composed of large and small "inescapable zones," pieced together like magnetic domains!
When you're lying in bed late at night scrolling through short videos, it's a negative "inescapable zone" - you probably won't suddenly put down your phone midway;
When you're eating, it's still an inescapable zone - you probably won't suddenly stop eating and go to the library to study;
When you're studying, it's a positive inescapable zone - after entering the state, you won't easily stop without encountering resistance.
Or perhaps you might say: "Wait, don't we always have some moments where we still have room for choice?"
But unfortunately, when pulled to larger scales, those surface-level freedoms are caged under even larger "inescapable zones":
- If you only slept three hours last night, your script is probably wasted for the whole day. Even if you force yourself to start studying, it's difficult to persist. You'll be trapped in the cycle of being tired on one side while alternating between short videos and games on the other, relying on the high stimulation of phones to maintain wakefulness. This can be coarse-grained into a day-level "inescapable zone";
- If this week you have completely no deadlines, reversed schedule, stuck at home with nothing to do, then your behavior will be trapped in the death cycle of continuous fatigue → decadence → reversed schedule → even more fatigue. This is another week-level "inescapable zone";
- As the final exam deadline approaches, your script this month is often: initially procrastinating and decaying → then easily entering study mode a few days before the exam, ultimately regretting why you didn't start earlier. Looking back, you find that at every semester's end, you're arranged crystal clear by this month-level "inescapable zone" script.
My friend, these layer upon layer nested scripts, cycles, and inescapable zones like Russian nesting dolls are the truth of our lives.
How many ways can we spend one minute? Perhaps hundreds or thousands: you might be scrolling through short video A, or scrolling through short video B, might be reading, or might be doing a certain problem.
But if we pull the time scale slightly larger, our one hour might only have a few dozen ways to spend it; might just be scrolling through short videos / studying / commuting / eating;
By one day, there might only be a dozen or so ways; one month, perhaps only seven or eight typical patterns; pulling to a one-year scale, you might be shocked to find that our year actually only has three or four rough scripts left.
As our perspective pulls back, progressively coarse-graining the entire event chain, the influence of those small-scale details becomes smaller and smaller, gradually averaged out. The entire system is increasingly dominated by those corresponding large-scale factors, such as environment, work, habits, personality, etc. Small-scale variables control small-scale scripts, large-scale variables control large-scale scripts:
- Your attention state controls your thoughts every second;
- The thing currently being done pulls your attention every minute;
- Today's schedule arrangement determines what you're specifically doing each hour;
- The energy and emotional state of recent days affects each day's specific arrangements;
- Going further up, your sleep routine, emotional cycles, environmental conditions, even your home layout, control your recent overall life state;
- And your identity, personality, and social situation determine your long-term rhythm, ultimately shaping the pattern of your entire life.
At each scale, once the corresponding factors are given, they become a solid "boundary condition," causing the system to spontaneously form several behavioral patterns that are easiest to stably exist at the current scale, as the current system's "stable states."
- When the boundary condition of "only slept three hours last night" is determined, alternating indulgence between scrolling through videos and playing games in these two small stable states is the behavioral pattern easiest to stably exist within the day. At this scale, a few minutes of attention, one hour of matters, are already unimportant;
- When the boundary conditions of "no recent deadlines," "reversed schedule," "stuck at home" are determined, all-day decadence cycling through late nights, fatigue, and indulgence among several small stable states is the behavioral pattern easiest to stably exist within the week. At this scale, one afternoon's energy, one or two days' schedules, are already unimportant;
- When the boundary conditions like "exam time," "personal habits," "external environment" are determined, the early-stage procrastination decadence small stable state + late-stage cramming small stable state is again this month's behavioral pattern easiest to stably exist. At this point, several days' state, one week's motivation, are already unimportant.
In this multi-scale large nesting doll, looking down, each stable state is composed of several smaller-scale stable states; looking up, several such stable states alternate and repeat, further combining to form larger stable state structures.
These stable states are highly stable, highly repetitive, and highly dependent on those key factors at corresponding scales. It's precisely these large and small influencing factors and stable states, interwoven together, that jointly constitute the "ecological environment" of our daily lives.
From this perspective, "free will" at the bottom layer is truly life's greatest illusion.
We possess free will completely every second, seem to possess free will every minute, relatively possess free will every hour, and by each day, each week, seem to no longer possess free will much. Macroscopically, we're just a piece of duckweed drifting with the waves in the vast ocean composed of environment, habits, circumstances, personality, and interest relations, our bodies involuntarily.
And the essence of all human self-control strategies is actually using the smallest-scale free will, with the support of various rules, to attempt from bottom-up to overcome large-scale unfavorable factors and shift larger-scale behaviors - this is undoubtedly as difficult as ascending to heaven.
All efforts and slogans, whether CTDP or otherwise, are merely attempting to stir up pale and powerless waves in this vast ocean. This is the tragedy we, with weak self-control, are naturally destined to encounter.
17
Now, we can finally look back and more clearly understand what bottlenecks local behavioral intervention strategies like CTDP will encounter.
The first bottleneck is the "scale limitation problem": CTDP can naturally only influence local behaviors, unable to shift those long-term factors behind these behaviors.
The core principle of CTDP is through a series of ingenious mechanisms to amplify rational tendency in the short term (such as one hour of focused tasks), reduce startup resistance, thereby greatly improving single-behavior execution. At the microscopic scale, it indeed demonstrates astonishing effectiveness.
But the problem is: Our lives are not pieced together from a string of isolated hours. "Not willing to start a task at this moment" is only the surface phenomenon, while those larger-scale factors causing this "unwillingness to start," such as energy state, emotional fluctuations, clear sense of goals, life rhythm, and even long-term habits, are the true essence.
When these large-scale factors are unfavorable to you, even using the most ingenious strategy to force yourself to study for one hour at the moment often has very limited effect:
- If you've recently frequently stayed up late and are physically and mentally exhausted, you won't even rationally want to study, and CTDP cannot solve the staying up late problem itself;
- If you recently have completely no clear tasks or urgent deadlines, then CTDP similarly cannot urge you to actively self-study, after all, you've never had the habit of self-studying.
Therefore, CTDP's first fatal limitation lies in it can only influence microscopic nodes, but cannot shift upward those macroscopic factors that determine our life's fundamental tone - it cannot make you energetic, nor can it make you mentally stable, much less shake your habits or life patterns.
The second bottleneck is the "stable state regression problem": Even if we temporarily change our life state, the system will spontaneously regress back to the original stable patterns.
As stated earlier, when larger-scale factors like energy state, life rhythm, mindset, and habits are determined, the system will naturally form a series of highly stable behavioral patterns. For example, at the beginning of winter vacation when just returning home, "playing games" and "scrolling through videos" might be the easiest life pattern to maintain, so your daily life will probably cycle repeatedly between "playing games" and "scrolling through videos."
CTDP's problem is that it can only temporarily intervene at certain nodes of the system. Even if it forcibly replaces certain hours with efficient study mode, so what?
The system's stable state is still that original stable state! Pulling the time scale longer, these few hours of efficiency will still be submerged in large chunks of playing games and scrolling through videos.
For those larger-scale (day-level, week-level) stable states determined by habits, sleep, and emotional states, these few hours of efficiency can't even stir up a wave, let alone change the stable state itself.
This spontaneous regression mechanism is precisely the fundamental reason for the frequent occurrence of "rebound," "returning to original state," and "intermittent efficiency" phenomena.
The third bottleneck, also the most fundamental and desperate, is the "binding force dissipation problem": Any attempt to deviate from the stable state is consuming resources (such as willpower) to maintain a metastable state, which necessarily cannot last long.
When a person's behavioral system forms some stable structure at large scales, it's like a self-perpetuating ecosystem, possessing natural "stable state attraction." Any effort to break free from this stable state essentially means needing to continuously invest various resources:
- Perhaps your precious willpower;
- Perhaps the sunk cost ingeniously designed by CTDP;
- Perhaps various binding rules, check-ins, supervision;
But the problem is: These resources are finite. When you try to maintain a "metastable state" that deviates from the original stable state, even if initially very successful, it will gradually wear away and exhaust under continuous negative factors, ultimately binding force collapses and regresses back to the original state. And aggressively changing the entire state all at once requires resources and strength that are difficult to maintain.
Is it possible for there to exist a "next better stable state" above the current stable state?
There indeed might be. Sometimes, even when large-scale factors are unfavorable, you might coincidentally be efficient for several consecutive days. But unfortunately, this state is often attainable but not sustainable. Before long, your life returns to its original state.
The most tragic thing is: Almost all self-control methods lack the power to change the entire stable state in a long-term, holistic, and immediate manner.
These self-control methods only use finite resources to support those bit of local binding rules, unable to shift the whole. When the shift fails, these strategies fall into the dilemma of "whack-a-mole": having constrained studying on this side, life order becomes chaotic on the other; having regularized sleep schedule on this side, emotional state collapses on that side.
This is because a large negative stable state is often interwoven from multiple small negative stable states: staying up late causes complete lack of energy, lack of energy makes it easier to indulge in games, indulging in games makes you chase stimulation, chasing stimulation makes you stay up later. This comprehensive negative state is like a Lernaean Hydra - strike its head and the tail arrives, strike its tail and the head arrives, strike its middle and both head and tail arrive.
Ultimately, you must admit a cruel reality:
Under the premise of finite resources, all efforts attempting to break free from the current base stable state almost face the same fate - brief success followed by rapid regression, unable to achieve a true stable state transition.
In summary, these three bottlenecks together constitute CTDP's theoretical limits that are difficult to transcend. To fundamentally break through these limitations, we must have a brand new, more globally-minded second-generation method.
And several years later, I finally found the key that can truly solve these problems.
18
It was a rainy night. At the time, I had just received my PhD offer but was then stuck by visa issues. Feeling helpless, I clicked on a xiangqi (Chinese chess) commentary video. It was about the famous "Lone Horse Slays King" game from the 1960 Sichuan chess players' visit to Wuhan performance match: Li Yiting versus Chen Deyuan.
At the end, the commentator mentioned:
The game has now reached a "checkmate in three moves" position.
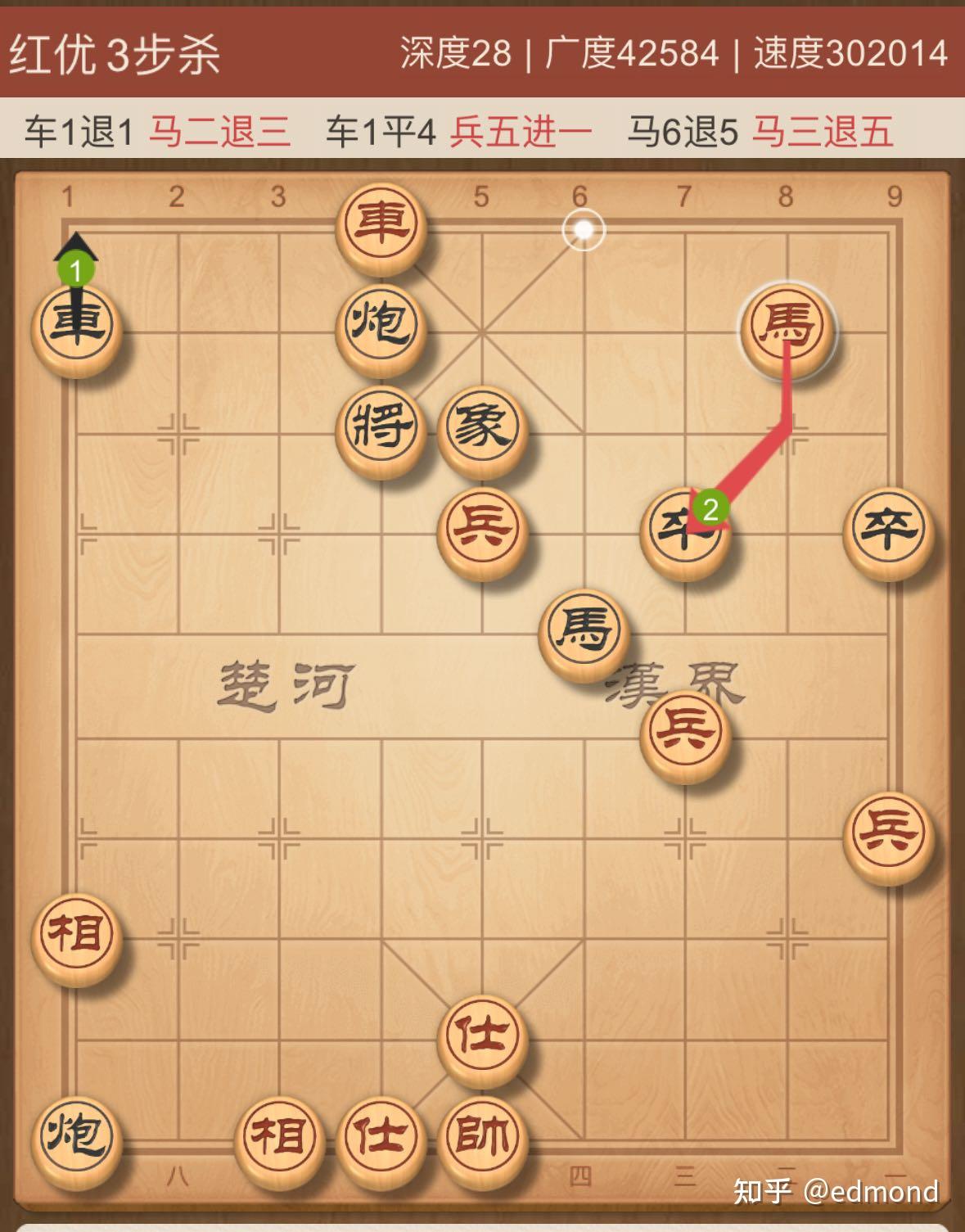
What does so-called "checkmate in three moves" mean?
It means that after entering this position, Black is actually already inevitably doomed. No matter how it responds, Red can always checkmate Black within three rounds. All of Black's struggles can only delay the time of being checkmated, and if the struggle is improper, it might even hasten this time.
So why did Black fall into such a dire situation?
Of course it's because its last move was wrong. If Black could take back the move and return to the previous step, perhaps it could avoid falling into the "checkmate in three moves" death trap; if returning to the previous step is still a "checkmate in four moves" and still cannot avoid being checkmated, then the move before that was already wrong. And so on.
You'll find that if we keep backtracking, we can necessarily backtrack to some move that would allow Black's hope of winning to reappear (at least within the computer's search range, Red cannot find a winning method).
And this point is precisely the key to breaking the deadlock for the second-generation method.
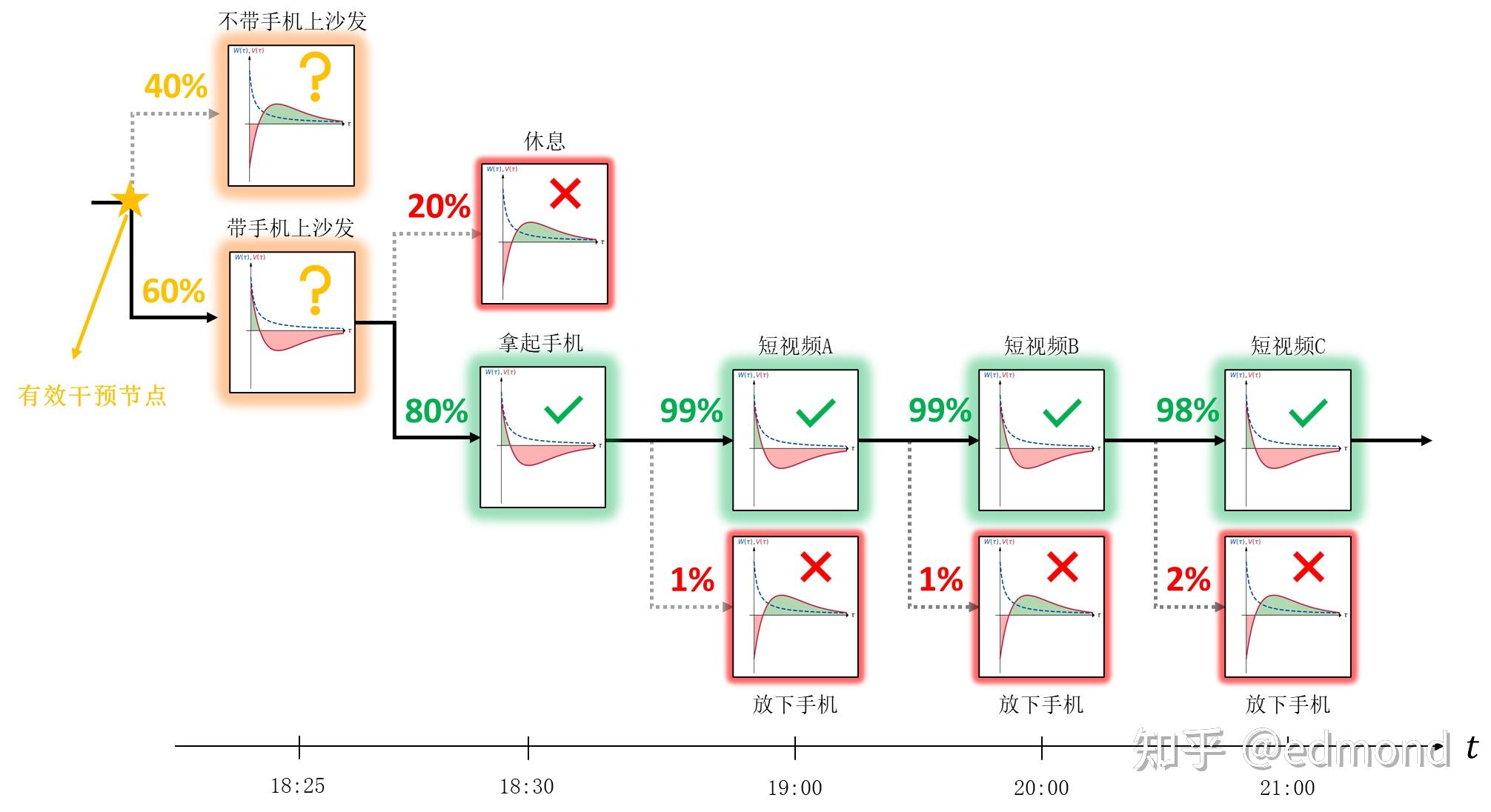
Back to the example of lying on the sofa playing with your phone at the beginning.
When lying on the sofa scrolling through videos, we've actually already unavoidably entered a death cycle. But what if we backtrack forward?
- To avoid starting to scroll through videos (99%:1%), we must avoid being on the sofa with phone in hand (80%:20%);
- To avoid being on the sofa with phone in hand, we must avoid bringing the phone onto the sofa (60%:40%);
- We can continue: to avoid bringing the phone onto the sofa, we must avoid entering a state where it's easy to bring the phone onto the sofa (50%:50%)...
Often in this series of event backtracking, the earlier you backtrack to, the smaller the tendency difference between the two options becomes!
Thus, we finally discovered an exciting law:
For any seemingly inescapable "inescapable zone," we can necessarily backtrack to some node - at this node, the tendency difference between the two options is small enough, entering the effective intervention range of free will, allowing us to truly avoid entering that final negative death trap.
— That is to say, every seemingly powerful, large-scale negative stable state can be mapped to a weak, small-scale effective intervention node!
And this node is where the true boundary of the "inescapable zone" lies, and also the only chance for small-scale will to resist large-scale unfavorable factors.
19
Seeing this, some people might say: Isn't this something everyone can think of? You've talked about so much profound theory, renormalization groups, behavioral stable states, inescapable zones, and so on. In the end, what you're saying is just that same old thing about not bringing your phone onto the sofa.
This kind of thing has been talked to death already. Today this blogger tells you not bringing your phone to bed can change your life; tomorrow that chicken soup tells you life turnaround starts from small things; the principle of staying away from temptation and preventing problems before they occur was discovered thousands of years ago. You use a pile of physics theories just to say this - isn't this using a cannon to shoot mosquitoes, making things unnecessarily mysterious?
But my friend, please don't be hasty. This is just our first building block.
As stated earlier, the types of negative states we face in life are actually extremely limited and highly repetitive; and for any given negative state, we can always find an effective intervention node through backtracking.
If we precisely apply constraints to it, we can achieve a "move a thousand pounds with four ounces" effect, preventing problems before they occur with minimal cost, avoiding entering those negative states from the very beginning. This constraint is the local optimal solution for this situation.
There are many such small technical optimal solutions. Let me give a few examples:
- For example, "never bringing your phone into the bedroom from the start" is much easier than "bringing the phone into the bedroom but remembering not to scroll on it." Then never bringing your phone into the bedroom from the start is naturally the optimal solution to solve the "scrolling phone before bed" problem;
- For example, "immediately taking a shower after arriving home and having nothing to do" is much easier than "after already lying on the sofa playing with phone, forcing yourself to get up and shower." Then having your phone automatically set a 15-minute countdown after detecting you've arrived home, during which you must start showering, is the optimal solution to solve "shower procrastination";
Of course, besides these simple and direct strategies everyone can think of, it can be extended much further:
- You can make certain behaviors simpler: For example, "no playing phone after 11 PM" can help you sleep early, but achieving it isn't easy; then, why not add "after 10:30 PM only allowed to play phone while standing" as an auxiliary. After all, going from playing phone to not playing phone is difficult, but going from playing phone to standing while playing phone, and from standing while playing phone to not playing phone, are both easier;
- You can also improve the overall state: For example, you might know that what you do after getting up each day can often set the tone for the whole day. Then not playing phone for 30 minutes after getting up each day, only doing proper things, can greatly improve the state for the entire day;
(Where does the binding force of these regulations come from? This will be explained later)
And most interestingly: Since negative states themselves are repetitive, then the "local optimal solutions" targeting these states are naturally equally repetitive!
In games like xiangqi and Go, such optimal operational plans targeting certain specific situations that can be repeatedly applied are called "joseki" (定式,fixed patterns).
So-called joseki are actually local optimal solutions summarized by countless predecessors after deep research: under specific local situations, both black and white players must strictly follow the joseki; if either side deviates from the script, they'll inevitably leave vulnerabilities.
Even in the ever-changing chess games, players can greatly improve their overall chess skill by mastering individual local joseki.
And we can also learn joseki like chess players, using a "divide and conquer algorithm" logic to break down negative states in life one by one:
- First, we can identify typical negative problems in life;
- Each negative problem can be further decomposed into several negative stable states;
- And each negative stable state can be mapped to corresponding effective intervention nodes through backtracking;
- Finally, for each intervention node, we can custom-design a precise "joseki" to break it.
This way, we can precisely concentrate finite self-control resources on those truly most critical nodes, performing reduced-scale strikes on those highly repetitive negative stable states one by one.
If four ounces can move a thousand pounds, then why not use eight ounces to move two thousand pounds, twelve ounces to move three thousand pounds, sixteen ounces to move four thousand pounds?
20
Even more wonderful: eight ounces might move more than just two thousand pounds.
Suppose we've truly found a local joseki and are willing to invest certain resources (such as method design, willpower investment, or external constraints) to implement it, successfully completely "banning" some negative state from life - for example, never again lying on the sofa with phone, or always immediately showering after arriving home.
Then, because its scale of action is long enough, this "joseki" itself will also become a large-scale factor, becoming one of the numerous boundary conditions influencing life's stable state!
At this point, is the stable state still that original stable state?
Obviously not. If we record the initial stable state as $E_0$, then when the first joseki is successfully introduced, your life will gradually enter a slightly improved metastable state $E_1$. In the new stable state $E_1$, because the overall state has improved by just that little bit, the difficulty of introducing the second joseki will decrease somewhat.
Similarly, after adding the second joseki, you enter the more optimized metastable state $E_2$. Introducing the third joseki in $E_2$ becomes even easier.
For example, if you achieve "not playing phone on the sofa," implementing "immediately shower after arriving home" will also be slightly easier; if you immediately shower after arriving home daily achieving a refreshed state, implementing "don't scroll phone before bed" will also be a bit easier because you've solved shower procrastination.
Each new joseki introduced might produce a "1+1>2" effect, ultimately in a "slicing sausage" manner, gradually improving your life, step by step transitioning toward a better long-term stable state. It's also possible that after you've added a dozen or so joseki, some difficult problem seemingly unrelated to them will unexpectedly naturally disappear after improvement in energy, habits, and other large-scale conditions.
As the Art of War states: "One skilled in warfare wins victories that are easily won."
After solving simple problems, originally medium-difficulty problems become simple problems; if we conquer this new simple problem, then originally difficult problems also become simple problems.
From beginning to end, we're solving simple problems.
Alright, we've found a series of joseki, each able to avoid entering a negative "inescapable zone" from the very beginning. But to thoroughly achieve large-scale stable state transition, we ultimately must still face that most fundamental challenge - the binding force limitation problem.
As analyzed earlier, all self-control strategies essentially use finite resources to support some local binding rules. This unavoidably leads to the "whack-a-mole" dilemma: just talked beautifully about going from $E_0$ to $E_1$, $E_1$ to $E_2$, but in reality, what might happen is you simply don't have this much energy to maintain these joseki.
- When you try to add a new joseki, some old joseki might suddenly collapse;
- Or you encourage growth by pulling up shoots, forcibly mounting a joseki with overly high requirements at the start. Before it can improve the overall state, maintaining it exhausts all resources;
- Or you introduce a new joseki incompatible with existing joseki, resulting in the entire system instantly crashing.
On one hand, adding new joseki requires investing more maintenance costs; but on the other hand, it can slightly improve the existing stable state, and over time will form habits, gradually reducing maintenance costs. Thus, the problem transforms into a competition between the speed of stable state improvement and the speed of maintenance cost increase.
Therefore, the sequence of introducing joseki itself is also crucial. Not just any arbitrary order can support you in reaching the next stable state. Additionally, where does the binding force of so many joseki come from?
To thoroughly solve this problem, we need to introduce a new ingenious algorithm - the "Recursive Backtracking Algorithm."
21
The so-called Recursive Backtracking Algorithm is actually a classic algorithmic thinking widely used in computer science. It's typically used to solve such problems: when you face a system with extremely huge possibilities (such as navigating a maze, playing chess), how to find a feasible, or even optimal path under the premise of finite resources.
The most typical example is the maze problem:
Imagine you're trapped in a maze. You don't know which path leads to the exit, and you have no map. All you can do is continuously try every walkable path:
- Each time you encounter a fork, you first randomly choose a path;
- If you walk down and discover this path doesn't work (dead end), you retreat to the previous fork and try another possible path;
- If the new path also doesn't work, you continue retreating, changing direction again, until you finally find a path leading to the exit.
This is the core logic of the "Recursive Backtracking Algorithm": Try → Fail → Withdraw → Change path → Continue trying, until success. Like in chess, continuously taking back moves to ensure finding a winning path.
So how should we apply the recursive backtracking algorithm to design the addition sequence of these "joseki"?
Suppose we've designed a series of joseki targeting various negative states in life, such as:
- Joseki (A) ensuring you always shower when arriving home;
- Joseki (B) ensuring you don't bring phone onto sofa;
- Joseki (C) ensuring you don't scroll Xiaohongshu at night;
- Joseki (D) ensuring you wash dishes promptly after meals;
- ...
At this point, we can use this " Joseki Tree" approach to organize and manage them:
- Joseki addition rules: If on a given day you successfully meet the requirements of a certain joseki, you can add it as a child node to the joseki tree, but add at most one per day. For example, if I find joseki H is highly related to existing joseki F, then I can add joseki H as a child node of F; if I find joseki E seems like an entirely new domain, I can also directly establish a new branch.
- Joseki deletion rules: Manage with a "stack structure." Once a joseki is deleted, simultaneously delete all its child nodes. For example, if joseki C has one failed execution, this indicates that the combination of joseki C and subsequent F, H is unstable, so generously delete it, simultaneously deleting subsequent F, H joseki. (Of course, in the future you can try adding joseki C again to the tree's end)
Through such repeated iteration, we naturally solve both the "joseki addition sequence" search problem and the "binding force source" problem:
- On one hand, joseki added more "naturally" and easier to maintain are more likely to stably remain at the root of this tree.
The reason is: in this iteration process, if a certain joseki's maintenance cost is too high and cannot be stably maintained under current conditions, it will naturally collapse and retreat back to the tree's end; conversely, those high-quality joseki that are added easily, maintained without burden, and significantly improve overall state can more easily be retained at the tree's root.
Over time, the nodes closest to the front of this joseki tree are instead all those seemingly trivial small rules that can bring huge positive effects. Can you guess what my current #1 root node joseki is? It's actually just "must wash dishes promptly after eating at home." Though it sounds unremarkable, it can truly avoid falling into a larger decadent state.
It's precisely these simple and tiny improvements accumulating at the root that make the entire joseki tree's foundation increasingly solid. Like "passive buffs" in games, continuously providing tiny improvements to the large state, supporting the entire tree to steadily advance step by step. This is the true "winning victories that are easily won."
- On the other hand, this stack structure will also naturally provide powerful binding force for newly added joseki.
Think about it: since introducing each joseki requires one day's effort, then if a joseki with four child nodes suddenly fails, this means your entire five days of effort, entire five joseki effective for self-control instantly wasted - and this loss occurs the instant you prepare to give up.
This is its second wonderful aspect: the closer to the root, the more child nodes a joseki has, the greater the loss cost, therefore the better it's protected.
Until finally, those joseki deeply buried at the root will gradually internalize into your habits because execution time has been long, requiring less and less resources to maintain, ultimately almost negligible. At this point, the constraint power saved can be invested in developing new joseki.
And this method is called Recursive Stabilization Iteration Protocol (RSIP).
It answers a widely existing question:
Under the condition of finite resources, how to govern a complex system's comprehensive negative stable state?
The answer is, we can target several small negative stable states through targeted backtracking, finding corresponding local optimal solutions as "joseki"; then, integrate them into a tree-structure diagram, using recursive backtracking search algorithm to explore the addition sequence of these joseki. Once a joseki cannot be maintained, decisively and recursively abandon it and its child nodes in the tree. Ultimately, only the path most beneficial to the entire system's stability can be retained - just as Qian Xuesen's ideological proposition advocated: "Not seeking advancement of individual technologies, only seeking overall design rationality."
Just like this, we finally achieved the miracle of self-control strategies - integrating numerous local optimal solutions into the joseki tree, accumulated, small-scale free will can be amplified to a magnitude sufficient to influence the global situation.
And from here, you can truly begin transforming sleep schedule, cultivating energy, improving health, adjusting life rhythm, eliminating habits you want to eliminate, cultivating habits you want to cultivate, making those previously seemingly immovable large-scale factors start working for you.
22
Of course, in practical application, if you want to gamify RSIP, it's also quite easy.
Because in reality, this method already has an almost identical counterpart - that's the famous National Focus Tree in the strategy game Hearts of Iron series:

In this game, each country has a huge "national focus tree," with the tree full of various diverse national focus nodes:
- Some are used for industrial expansion;
- Some strengthen military construction;
- Some determine diplomatic direction;
Each national focus can provide players with various bonus effects, and choosing and designing one's own country's national focus tree is one of this game's greatest charms.
In practical application, I also like using mind mapping software (such as MindMaster) to manage such national focus trees. The process of designing various national focuses for RSIP is actually quite interesting:
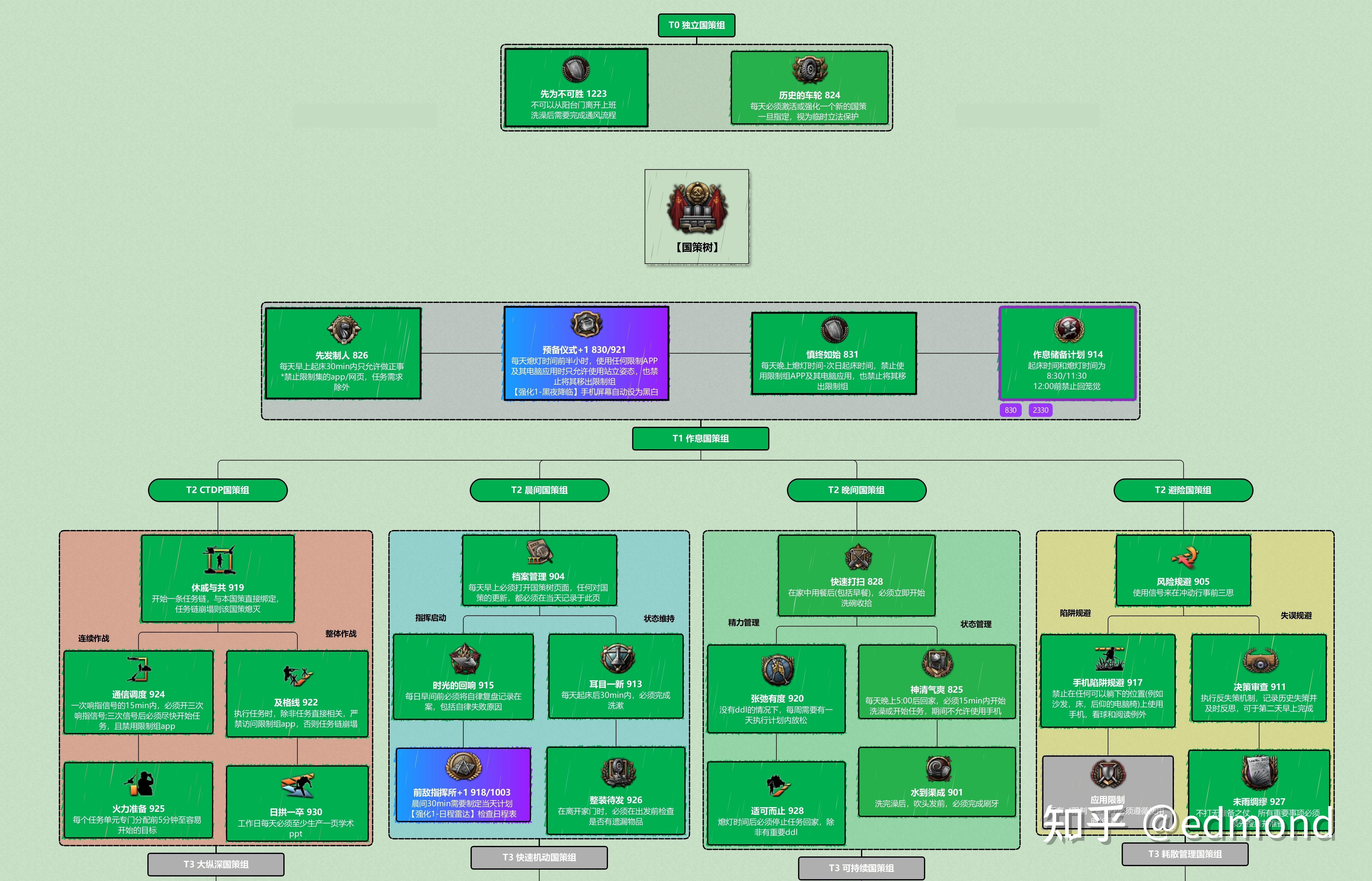
- For example, targeting the evening shower procrastination problem, the "national focus" I designed is: Using iPhone's automation function, once evening positioning detects returning home, automatically start a 15-minute countdown, must enter bathroom to start showering before countdown ends;
- For another example, to address the problem of playing with phone after waking up in the morning causing the whole day to be muddled, the "national focus" I designed is: Strictly prohibit using phone for the first 30 minutes after waking, can only do proper things like washing up, organizing, eating breakfast, or checking emails, thereby activating the day's state;
- And to ensure the RSIP system itself can continuously operate stably, I also specially designed a "root national focus" at the very root: During the morning wake-up period, must open the national focus tree mind map page, and must add one new national focus every day.
Meanwhile, if you want to make it more fun, national focuses can also be "strengthened and upgraded" like game equipment.
For example, a progressible national focus called "Sleep Reserve Plan" can be arranged under the early sleep/early rise national focus, progressively advancing phone curfew/wake time - if one day you successfully achieve 22:45/7:45, record it as "Enhancement +1"; and on another day achieve 22:40/7:40, can upgrade to "Enhancement +2."
This upgradeable national focus can protect its base node through stored redundancy. Because even if one time you have to stay up late due to circumstances, you can release it, return to the +0 state, and your habitual sleep rhythm won't suddenly collapse (leading to its child nodes also being difficult to maintain).
In fact, the vast majority of current online discussions about self-control are actually unsystematic, extremely fragmentary "local suggestions." Today this marketing account tells you locking up your phone can keep you away from it; tomorrow that chicken soup blogger makes a whole video series just telling one old cliché about breaking down goals. They all vehemently claim that after listening to their methodology, your life will be overturned and changed. Unfortunately in reality, most of these experiences are just life hacks at best.
However, I don't completely oppose these experiences, but rather provide a framework to design these locally useful techniques into individual "national focuses," incorporating them into this system.
Future applications are yours to freely explore.
Afterword
23
The genesis of this article stemmed from my accidentally seeing a note about ADHD by @Allvinn on Xiaohongshu. At the time, I was just touched by my own years of bitter struggle with ADHD and self-control problems, and casually wrote some comments, unexpectedly giving birth to the idea of organizing these accumulated thoughts from over the years into writing.
Honestly speaking, I'm not any particularly excellent person. Just a very ordinary student who grew up in parents' doting and addiction to games from childhood, long plagued by terrible habits and severe self-control problems. Throughout my past life, my grades also often struggled repeatedly between rock bottom and top ranks. Fortunately, I stumbled along all the way, also getting into graduate and doctoral programs, becoming an ordinary scientific research brick mover, able to quietly do things I enjoy in one small laboratory.
In fact, most people have more or less thought about things related to "self-discipline" since enlightenment, and I'm just someone who happened to sustain this thinking a bit longer.
However, at the end of the article, I actually want to convey a message more:
I am extremely sensitive to the excessive deification and promotion of "self-discipline" and "methodology" by many marketing accounts and knowledge bloggers now. As if just learning their methodology, attending their training camps, one becomes self-disciplined, hardworking, defying fate changed, starting to counterattack.
I don't think so.
In fact, self-control methods have never been any magic pill to make life cheat-mode. Even if you achieve absolute self-discipline, so what? This is still just one piece among countless puzzle pieces in your life, and not necessarily the most important piece.
In life, there are many puzzle pieces more important than this - physical and mental health, family environment, social resources, personal personality, interpersonal relationships, furthermore the elusive luck, even the era you're in itself - they can all like fate's stones, like nails on Newton's board, push a young person's industrious and self-disciplined efforts toward unknown distances.
Our era indeed has quite a few people suffering from lack of self-discipline; but there are also many suffering from excessive self-discipline, from internal pressure and obsession with "excellence." Self-discipline has never been something everyone needs; what many people need more is relaxation, healthily and freely doing things they enjoy.
Therefore, this article's efforts are actually just attempting to help some people, to some degree, solve some problems.
Not everyone needs self-discipline;
Not everyone who needs self-discipline is suitable for the methods proposed in this article;
Not everyone suitable can understand it;
Much less can everyone who understands it truly benefit from it.
But I myself have genuinely experienced, in the past decade or so, the regret, missed opportunities, internal consumption and sense of powerlessness caused by lack of self-discipline.
In the vast sea of humanity, might there be a second me? If there truly is such a person, I'm willing to hold up a small umbrella for him/her.
Even if this umbrella can only help one person similar to my former self among every thousand people in the world, then all of this would be worth it enough.
24
Having spoken about individuals, let's talk about society.
To this day, society actually already has a certain degree of understanding and tolerance for depression. But in comparison, understanding and tolerance for "lack of self-control," "procrastination," "ADHD" and other problems is still far from enough.
Now, for depression patients, more and more enlightened people are beginning to realize this is a genuine psychological illness, not simply "矫情" (being pretentious) or "can't think it through." They're starting to try understanding the real pain patients face from attention collapse, loss of interest, sleep disorders, emotional dullness, and even somatization.
However, toward ADHD patients and those with long-term self-control deficiency, people's attitudes are often still crude, harsh, lacking empathy:
- Their procrastination, laziness, difficulty taking action are often mocked as "lazy people finding excuses";
- Their falling into patterns of attention diffusion and easy addiction is seen as "poor self-control" and "can't control themselves";
- Even many ADHD patients who struggle upward using various means, while regretting their loss of control, often get cold sarcastic remarks like "self-touching," "浮气躁" (impetuous), "just pretending to work hard," "suitable for factory work."
In such a cultural atmosphere, people refuse to respect the objective fact that "human self-control has limitations." Many people are unwilling to admit that human subjective agency is not infinite, that it's limited by neural structure, hormone levels, psychological state, external environment, long-term habits and many other objective factors.
"Lack of self-control" has never been an attitude or mindset problem that can be solved through motivation and persuasion, but rather an objectively existing engineering problem, systems problem, even medical problem.
Attempting to use slogans, chicken soup, whip-and-carrot motivational traditional psychology preaching to solve such problems is like using "you're too fragile," "be more optimistic," "just think it through and you'll be fine" to comfort a depression patient - equally laughable.
I really like that line from The Great Gatsby:
"Whenever you feel like criticizing anyone, just remember that all the people in this world haven't had the advantages that you've had."
Just as human sorrows and joys are not mutually intelligible, in the matter of self-discipline, human conditions in all aspects are also not mutually intelligible.
- Some people cultivated good habit foundations from childhood, in an environment full of progressive atmosphere. They might only need to make a plan list, smile in the mirror a few times each day to easily achieve Easy-difficulty self-discipline;
- But some people have been addicted to phones since childhood, with lazy habits and decadent family environment. On this foundation, achieving self-discipline might be Hard-difficulty hell.
Self-control, as something we've commonly faced since childhood, has been more or less thought about by almost everyone. So if all these people have thought about "how to self-control," what would be the result?
This forms society's general cognition of "self-discipline" - either stopping after fifty steps, or stopping after a hundred steps.
The essence of self-control methods is just a prosthesis for self-control deficiency. Just like crutches and wheelchairs are prostheses for disabled people's motor abilities. Healthy people don't need crutches and wheelchairs, and patients whose injuries have healed also no longer need crutches and wheelchairs.
Once this gap is filled, people no longer pursue more advanced crutches and wheelchairs. So the answer becomes "the pony crossing the river": Easy-difficulty people will say smiling in the mirror works; Medium-difficulty people will suggest you put down your phone and make plans; Hard-difficulty people think you must rely on external supervision, even live-streaming while studying.
And an extremely counterintuitive social phenomenon precisely comes from this.
In personal achievement, self-discipline is actually just one of many factors. Those Easy-difficulty players, besides being easier to achieve self-discipline, also possess better habit foundations, environmental help, and social resources, thus also more easily achieving success. Therefore, if you observe those who achieved success, you'll find they're probably precisely from "Easy difficulty." In their eyes, self-discipline is as easy as doing push-ups in an elevator.
This creates a strange survivorship bias - the more successful people are, the more likely they are to use ineffective self-discipline methods. Just as healthier people increasingly lack real experience using crutches and wheelchairs.
Even more terrible is when society establishes these Easy-mode players as role models for everyone, granting them supreme discourse power, it forms an extremely cruel, "why not eat meat porridge" atmosphere toward those truly lacking self-control.
I don't know how many times I've scrolled past comments from so-called "people who've been there," who sneer at self-control methods. In their mouths, "back in our day we just had one path up Mount Hua, just do it and it's done, just work hard and it's done. Where's all this beating around the bush?"
There was also once when I scrolled past an interview video with a gaokao (college entrance exam) top scorer. When the host asked about "how to view many students being decadent, depressed, lacking motivation, unable to self-discipline," that top scorer paused slightly, raised a proud yet tender face, and expressed sincerely and confusedly:
"To be honest, I really can't quite understand why some people would have no motivation."
Perhaps in their world, self-discipline is as simple as breathing and walking, motivation as natural as the daily sun. So they perhaps aren't acting with malice, just purely unable to understand.
More often, we can also see many marketing accounts and self-media bloggers with bright shiny titles sharing so-called "self-discipline experiences." Clicking in to look, the whole article talks about "because of love," "because of high energy" - this is still normal. More bloggers are instead giving classes, opening their mouths about "thought models," closing their mouths about "cognitive upgrades," talking about Dao, talking about Zen, talking about energy sublimation, talking about spiritual healing.
I'm not criticizing those who have smooth sailing - this isn't their fault.
I'm just trying to point out a fact - human experiences are not naturally mutually intelligible; human subjective effort also can never exist independently from objective conditions.
Of course, we can't expect everyone to understand complex psychological mechanisms and behavioral science. We can't even expect everyone to be sufficiently kind.
But I'm willing, beyond those who walked fifty or a hundred steps, as an ADHD patient with extremely poor self-control foundation, to embark from the lowest starting point on that thousand-step long journey. So much so that behind these two generations of methods are hundreds of failed ideas, hundreds and thousands of methodologies that have appeared on the current internet and in related books - I've thought about, tried, and analyzed every one. After this, I've finally reached the endpoint - finally possessing a normal person's self-discipline level.
Perhaps this path only suits me alone. But dear stranger, if it can help even one person, even just you, then I also feel all of this is worth enough.
I hope it can, amidst the currently overwhelming "put down your phone," "make plans," imagine the future, "tell yourself" type permutation-combination superficial "advice," walk a completely different path belonging to "technology."
"Cavalry drenched in sweat and blood, attack speed equivalent to 20th century armored divisions; Northern Song's bed crossbows, firing range reaching fifteen hundred meters, comparable to 20th century sniper rifles; but these are still just ancient cavalry and bows, impossible to contend with modern forces. Basic theory decides everything - the Futurist school clearly saw this point."
This is the truest reason I wrote this article.
25
Finally, let me say: the author will not use this content itself for any profit, will not establish any paid communities, and doesn't need follows and likes. Money can be earned and also spent, follows can gather and also dissipate, but thought and technology are always there.
If this article can fortunately benefit some people, my only wish is not your likes and returns, but rather hoping more people can have one more portion of respect and empathy toward those whose conditions, habits, achievements, and education are inferior to their own, and I'll be satisfied.
Finally, please let me imitate an MIT License as the ending:
Anyone has the right to use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of the content in this article for free and without restriction, and allow this content to be used for commercial purposes without needing to obtain permission from the author or pay any fees - only needing to credit the original author. All income generated from adapting this article into videos, comics, promotional articles, etc. belongs to the adapter; this article's author takes no share. Additionally, all tips, gifts and other income will be entirely used to promote this content itself. However, if the author personally contributes labor and participates in commercialization projects based on this article (such as planning, cooperative development, etc.), then related rights and interests shall be separately agreed upon according to normal commercial standards.
The purpose of this article is precisely what I mentioned at the end of this answer - Proletarians of the world, unite!